Ch3. RDD로 프로그래밍하기
RDD (Resilient Distributed Dataset)
Data Sharing 도구로 RAM을 사용
Disk Storage (HDFS) -> RAM Storage (RDD)
Spark도 JVM위에서 수행
여러 분산 노드에 걸쳐서 저장되는 변경이 불가능 (immutable)한 데이타(객체)의 집합
각각의 RDD는 여러개의 파티션으로 분리됨 (partitioned collections of records)
RAM을 Read-Only로 사용해 보자
스토리지->RDD 변환, RDD->RDD 만 가능
RDD 생성
코드에서 생성된 데이터 저장
- ex> JavaRDD<String> lines = sc.parallelize(Array.asList(“first”,”second”))
외부 파일 로딩 or 외부 데이터셋 로드 (S3, HDFS, Hbase 등)
- lines = sc.textFile(“/path/filename.txt”)
RDD Operation
Transformation
기존의 RDD 데이타를 변경하여 새로운 RDD 데이타를 생성해내는 것.
ex> filter: 특정 데이타 추출, map: 데이타를 분산 배치
변환 함수 목록:https://spark.apache.org/docs/latest/programming-guide.html\#transformations
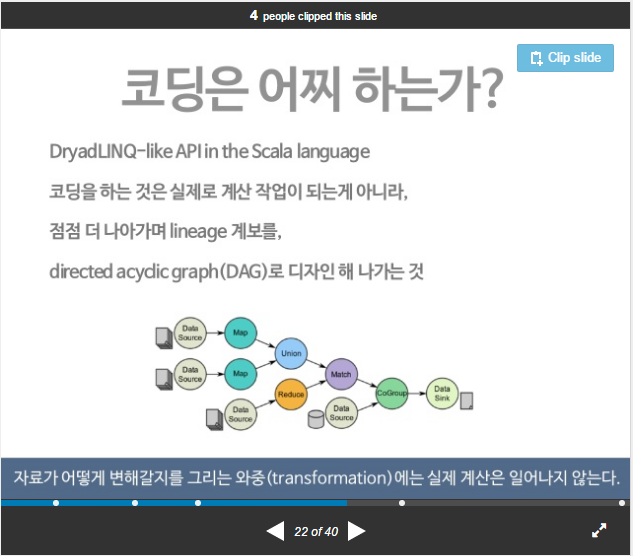
lineage 계보를 DAG (Direct Acydic Graph)로 디자인 해나가는 것
Transformation 중에 실제 계산은 수행되지 않음
DB의 쿼리 플랜과 유사하다고 생각됨
- 메타 데이터에 연산이 요청되었다는 사실만 기록
Action
RDD 값을 기반으로 무엇인가를 계산해서(computation) 결과를 (셋이 아닌) 생성해 내는것
- 새로운 액션을 호출할 때마다 전체 RDD가 수행되는 비효율성 -> persist 사용
RDD 데이터 로딩 방식
Lazy Execution
Transformation 중에 실제 데이터 로딩은 되지 않고 lineage만 생성됨
Action에 해당하는 함수
RDD 데이터 스케줄링
2가지 타입 dependency
narrow dependency
한 노드로 동작
메모리 속도로 동작
파티션이 깨져도 해당 노드에서 복원 가능
Map, filter, union, join with inputs co-partitioned
wide dependency
여러 노드로 동작
노드끼리 셔플이 발생해야 함
파티션이 깨지면 복구이슈가 있음
네트워크를 타기 때문에 네트워크 속도로 동작
groupByKey, join with inputs not co-partitioned
클러스터에서 Spark 수행
- 구성


RDD 저장/삭제
저장
persist(), cache()
cache()는 persist() 에서 저장 옵션을 MEMORY_ONLY로 한 옵션과 동일
메모리와 디스크 두 가지 영역을 사용
옵션에 따라 RDD 저장영역 지정 가능
Serialzied를 하게 되면 메모리 사용용량은 줄일 수 있으나, read/write 시에 DeSerialzied를 수행하게 되어 CPU사용량이 증가하게 됨
삭제
- 기본적으로 LRU (Least Recently Used) 알고리즘 (가장 근래에 사용되지 않은 데이타가 삭제되는 방식)에 의해서 삭제
참고 URL

hello