참고 :https://github.com/andstudy/afternoon/blob/master/2015/learningSpark/ch5_data.pdf
- 스파크 데이터 불러오기 & 저장하기
3가지 종류 데이터 소스
파일포맷(TEXT, JSON, 시퀀스 파일, 프로토콜 버퍼 등)과 파일시스템 ( NFS, HDFS, S3 등)
스파크 SQL을 사용한 구조화된 데이터
- JSON, HIVE 같은 구조화 된 데이터 지원 등
데이터베이스와 키/값 저장소
- 카산드라, HBase, Elastic Search, JDBC 지원 등
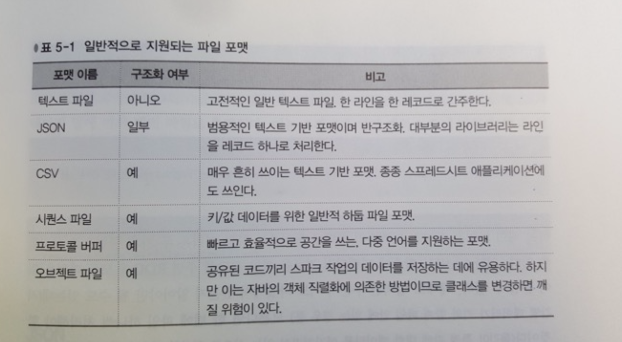
파일포맷
구조가 없는 텍스트파일 부터 구조화된 json, 구조화 포맷인 시퀀스 파일까지 지원
텍스트 파일
단일파일
- var input = sc.textFile(“file://home/holden/repos/spark/README.md”)
다중파일
- var input = sc.wholeTextFile(“file://home/holden/repos/spark/”)
파일입력명에 와일드카드(*) 지원
텍스트파일 저장
- saveAsTextFile(outputFile)
JSON
텍스트 로딩 후 json parser 사용
json 직렬화 라이브러리 사용
------------------------------------------ -- CU로그 -- Request Header를 파싱한 경우 -- request path : /v1/sdk/log/cu -- 정규표현식 : \{"@timestamp":"(.+?)","level":"(.+?)","level_value":(.+?),"req":\{"method":"(.+?)","uri":"(\/v1\/sdk\/log\/cu)","path":"(.+?)","header":\{"authorization":"(.+?)","gcs-device-token":"(.+?)","content-length":"(.+?)","x-forwarded-proto":"(.+?)","host":"(.+?)","x-forwarded-port":"(.+?)","connection":"(.+?)","x-forwarded-for":"(.+?)","accept-encoding":"(.+?)","user-agent":"(.+?)\"},"params":(.+?)\},"res":\{"statusCode":(.+?),"header":(.+?),"body":(.+?)\},"elapsed":(.+?),"os":"(.+?)","osVersion":"(.+?)","requestId":"(.+?)","appId":"(.+?)","sdkVersion":"(.+?)","model":"(.+?)","location":"(.+?)","locale":"(.+?)","userId":"(.+?)","remoteAddress":"(.+?)"\} ------------------------------------------ USE BBM; DROP TABLE IF EXISTS ACCESS_LOG_CU; CREATE EXTERNAL TABLE ACCESS_LOG_CU ( time_stamp string comment '@timestamp' ,level string comment 'level' ,level_value string comment 'level_value' ,req_method string comment 'req.method' ,req_uri string comment 'req.uri' ,req_path string comment 'req.path' ,req_header_authorization string comment 'req.header.authorization' ,req_header_gcsdevicetoken string comment 'req.header.gcs-device-token' ,req_header_contentlength string comment 'req.header.content-length' ,req_header_xforwardedproto string comment 'req.header.x-forwarded-proto' ,req_header_host string comment 'req.header.host' ,req_header_xforwardedport string comment 'req.header.x-forwarded-port' ,req_header_connection string comment 'req.header.connection' ,req_header_xforwardedfor string comment 'req.header.x-forwarded-for' ,req_header_acceptencoding string comment 'req.header.accept-encoding' ,req_header_useragent string comment 'req.header.user-agent' ,req_params string comment 'req.params' ,res_statuscode string comment 'res.statusCode' ,res_header string comment 'res.header' ,res_body string comment 'res.body' ,elapsed string comment 'elapsed' ,os string comment 'os' ,osversion string comment 'osVersion' ,requestid string comment 'requestId' ,appid string comment 'appId' ,sdkversion string comment 'sdkVersion' ,model string comment 'model' ,location string comment 'location' ,locale string comment 'locale' ,userid string comment 'userId [로그인한 사람을 나타냄]' ,remoteaddress string comment 'remoteAddress' ) COMMENT 'CU Access Log [Access Log 에서 path="/v1/sdk/log/cu" 인 데이터 정규식으로 확인 (path 값은 변하지 않음)]' PARTITIONED BY ( day string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( "input.regex" = "\\{\"@timestamp\":\"(.+?)\",\"level\":\"(.+?)\",\"level_value\":(.+?),\"req\":\\{\"method\":\"(.+?)\",\"uri\":\"(\\/v1\\/sdk\\/log\\/cu)\",\"path\":\"(.+?)\",\"header\":\\{\"authorization\":\"(.+?)\",\"gcs-device-token\":\"(.+?)\",\"content-length\":\"(.+?)\",\"x-forwarded-proto\":\"(.+?)\",\"host\":\"(.+?)\",\"x-forwarded-port\":\"(.+?)\",\"connection\":\"(.+?)\",\"x-forwarded-for\":\"(.+?)\",\"accept-encoding\":\"(.+?)\",\"user-agent\":\"(.+?)\\\"},\"params\":(.+?)\\},\"res\":\\{\"statusCode\":(.+?),\"header\":(.+?),\"body\":(.+?)\\},\"elapsed\":(.+?),\"os\":\"(.+?)\",\"osVersion\":\"(.+?)\",\"requestId\":\"(.+?)\",\"appId\":\"(.+?)\",\"sdkVersion\":\"(.+?)\",\"model\":\"(.+?)\",\"location\":\"(.+?)\",\"locale\":\"(.+?)\",\"userId\":\"(.+?)\",\"remoteAddress\":\"(.+?)\"\\}" ) STORED AS TEXTFILE LOCATION 'hdfs://neohcs-cluster/user/hdfs/bbm/access_log' ;
json 데이터를 사용자 하둡포맷을 사용
json 불러오기
python : import json
scalar : jackson
- json 저장하기
CSV & TSV
일관성이 깨지는 경우
- newline, escape 문자, non-ascii 문자, 정수가 아닌 숫자 등
CSV 불러오기
- python : import csv, import StringIO
- CSV 저장하기
시퀀스 파일
키/값 쌍의 비중첩 파일로 구성된 인기 있는 하둡파일포맷
동기화 표시를 갖고 있어 스파크가 해당 부분까지 파일 탐색을 했을 때 필요한 레코드 경계까지만 재동기화 할 수 있도록 해줌
스파크가 여러 노드에서 병렬로 시퀀스 파일을 효율적으로 읽을 수 있도록 해줌
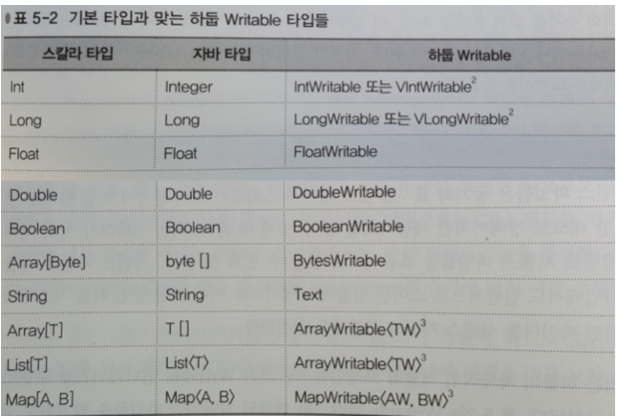
하둡의 자체 직렬활 프레임워크로 쓰는 Writable 인터페이스를 구현한 데이터로 구성됨
시퀀스 파일 불러오기
var data = sc.sequenceFile(inFile, “org.apache.hadoop.io.Text”, “org.apache.hadoop.io.IntWritable”)
inFile : path
org.apache.hadoop.io.Text : keyClass
org.apache.hadoop.io.IntWritable : valueClass
시퀀스 파일 저장하기
기본타입 : PairRDD를 saveAsSequenceFile(path)를 호출
가변타입 : 저장하기 전 map을 사용하고 데이터 변환
오브젝트 파일
오브젝트 파일은 시퀀스 파일에 대해 단순한 포장을 더해 값만을 가진 RDD를 편법적인 방법으로 저장
오브젝트 파일은 자바의 직렬화를 사용함.
대부분 스파크 내에서 스파크 작업들끼리 통신하기 위한 용도로 사용됨
하둡 입출력 포맷
신/구 하둡 API를 모두 지원함.
하둡 출력 포맷으로 저장하기
파일압축
디스크 공간과 네트워크 부하를 줄이기 위해 출력 포맷에 데이터 압축 코덱 지정
파일시스템
로컬/일반 FS
- 파일들이 클러스터의 모든 노드애서 동일경로에 있어야 함.
S3
HDFS
스파크 SQL로 구조화 데이터 다루기
스파크 SQL에 SQL쿼리문을 날려서 데이터 소스에서 실행시키고, 해당 레코드당 하나씩의 row객체로 이루어진 rdd로 가져오는 것을 의미
Hive
JSON
데이터 베이스
JDBC 연결
카산드라
HBase
일래스틱 서치