Ch8. 스파크 최적화 및 디버깅
- 참고
SparkConf 로 스파크 설정하기
- 스파크의 주된 설정 메커니즘은 SparkConf 클래스를 통해 설정되며, SparkConf 객체는 재정의 가능한 파라메터의 키/값 페어를 갖음
set(String key, String value): SparkConf, get(String key): String 등의 메소드를 통해 설정 값을 추가나 가져올 수 있음
- 그 외 setAppName)(String name): SparkConf, setMaster)(String master): SparkConf 등의 유용한 메소드가 존재함scala> val conf = sc.getConf
scala> val conf = sc.getConf
conf: org.apache.spark.SparkConf = org.apache.spark.SparkConf@672549f3
scala> conf.get("spark.app.name")
res12: String = Spark shell
scala> conf.get("spark.master")
res13: String = local[*]
- spark-submit 도구를 사용하여 실행 어플리케이션의 설정값을 동적으로 지정해 줄 수 있음
# Run application locally on 8 cores
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[8] \
/path/to/examples.jar \
100
# Run on a Spark standalone cluster in client deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# Run on a Spark standalone cluster in cluster deploy mode with supervise
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# Run on a YARN cluster
export HADOOP_CONF_DIR=XXX
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \ # can be client for client mode
--executor-memory 20G \
--num-executors 50 \
/path/to/examples.jar \
1000
# Run a Python application on a Spark standalone cluster
./bin/spark-submit \
--master spark://207.184.161.138:7077 \
examples/src/main/python/pi.py \
1000
# Run on a Mesos cluster in cluster deploy mode with supervise
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master mesos://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
http://path/to/examples.jar \
1000
- 실행하는 애플리케이션의 SparkConf 는 한 번 SparkContext의 생성자에 넘겨지고 나면 파라메터 수정이 불가능함
- SparkConf 설정 파라메터 우선 순위
- 사용자 코드 정의 > spark-submit 절달 플래그 > spark-submit 설정 파일 > default 설정 값
- SparkConf Default Values
- 데이터 셔플 시 사용할 로컬 저장 디레터리 지정 옵션 (단독모드 또는 메소스 모드)
- conf/spark-env.sh 내 SPARK_LOCAL_DIRS 변수 - 쉼표로 구분하여 경로를 지정
실행을 구성하는 것: 작업, 태스크, 작업 단계
- 스파크 어플리케이션 실행 코드의 실행 계획을 파악하여 최적화 작업이 가능함
scala> val sqlContext = new SQLContext(sc)
warning: there was one deprecation warning; re-run with -deprecation for details
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@6e956361
scala> sqlContext.read.json("hdfs://localhost:9000/source").createOrReplaceTempView("source")
scala> val fields = "os,store,country,channel,appid,ug1,ug2"
fields: String = os,store,country,channel,appid,ug1,ug2
scala> val arrFields = fields.split(",")
arrFields: Array[String] = Array(os, store, country, channel, appid, ug1, ug2)
scala> val sqlRDD = sqlContext.sql("SELECT %s FROM source".format(fields)).rdd
sqlRDD: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[43] at rdd at <console>:34
scala> var resultMap = Map[String, Set[String]]()
resultMap: scala.collection.mutable.Map[String,scala.collection.mutable.Set[String]] = Map()
scala> sqlRDD.map { x => {
| for (k:String <- arrFields) {
| if (x.schema.exists { x => x.name == k } && x.getAs[String](k) != null) {
| val v = x.getAs[String](k)
| if (resultMap.contains(k)) {
| val values = resultMap.getOrElse(k, "").asInstanceOf[Set[String]]
| if (values != "" && !values.contains(v)) resultMap.updated(k, values += v)
| } else {
| resultMap += (k -> Set(v))
| }
| }
| }
| }
| }
res80: org.apache.spark.rdd.RDD[Unit] = MapPartitionsRDD[44] at map at <console>:41
scala> sqlRDD.toDebugString
res81: String =
(1) MapPartitionsRDD[43] at rdd at <console>:34 []
| MapPartitionsRDD[42] at rdd at <console>:34 []
| MapPartitionsRDD[41] at rdd at <console>:34 []
| FileScanRDD[40] at rdd at <console>:34 []
- 스파크 스케쥴러는 액션을 수행할 때 필요한 RDD 연산의 물리적 실행 계획을 만듬
스파크 스케쥴러는 연산되는 마지막 RDD 에서 시작하여, 연산해야 할 것을 역으로 추적 함
스파크의 내부 스케줄러는 RDD가 이미 메모리나 디스크에 캐싱 되어있을 때, 건너뛰기를 시도하여, 해당 작업을 생략함
- 재연산이 필요한 작업은 persist() 등을 통해 캐싱 처리하면 성능을 높일 수 있음
스파크의 대부분의 로깅이나 조작은 stage, task, shuffle 등의 단어로 표현 됨
스파크의 실행 중에는 다음의 단계 들이 발생함
- 사용자 코드가 RDD의 DAG를 정의
- DAG가 액션의 실행 계획으로 변환
- 테스크들이 스케줄링 되고, 클러스터에서 실행
정보 찾기 - 스파크 웹 UI
YARN 클러스터 모드인 경우 어플리케이션 드라이버가 클러스터 내부에서 실행 되어, ResourceManager 를 통해 UI에 접근해야함
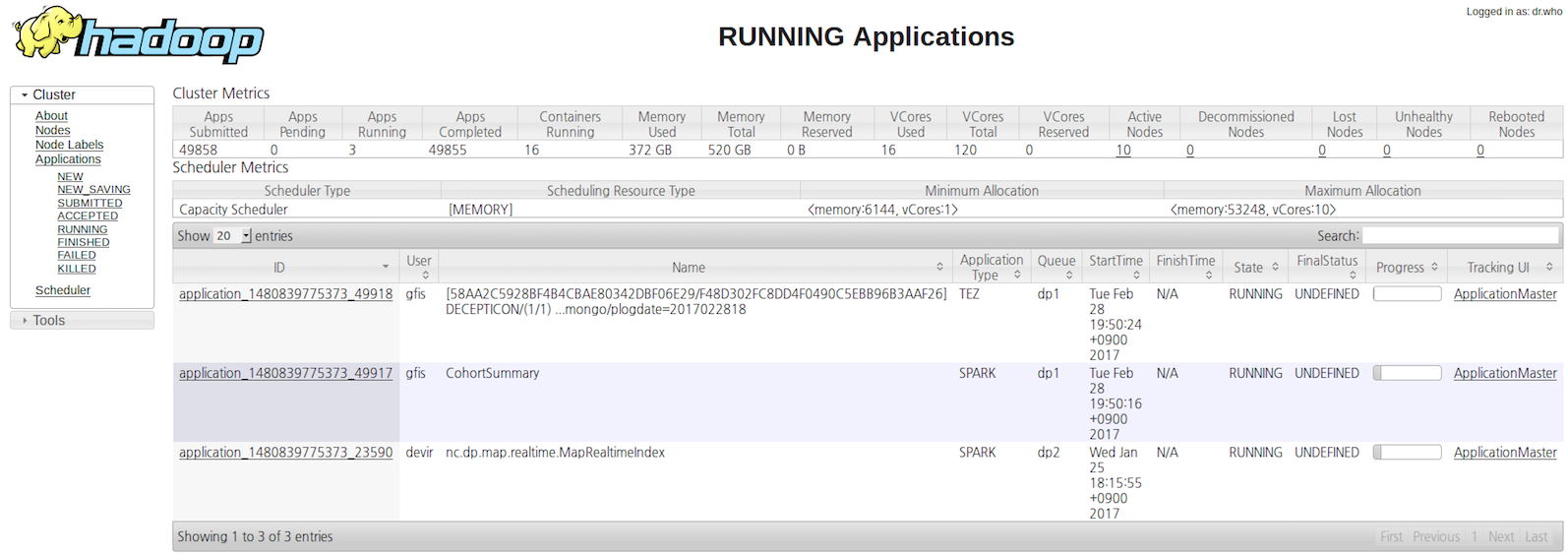
spark Jobs 페이지 - 실행 중이거나 최근에 완료 된 작업들에 대한 세부적인 실행 정보를 보유
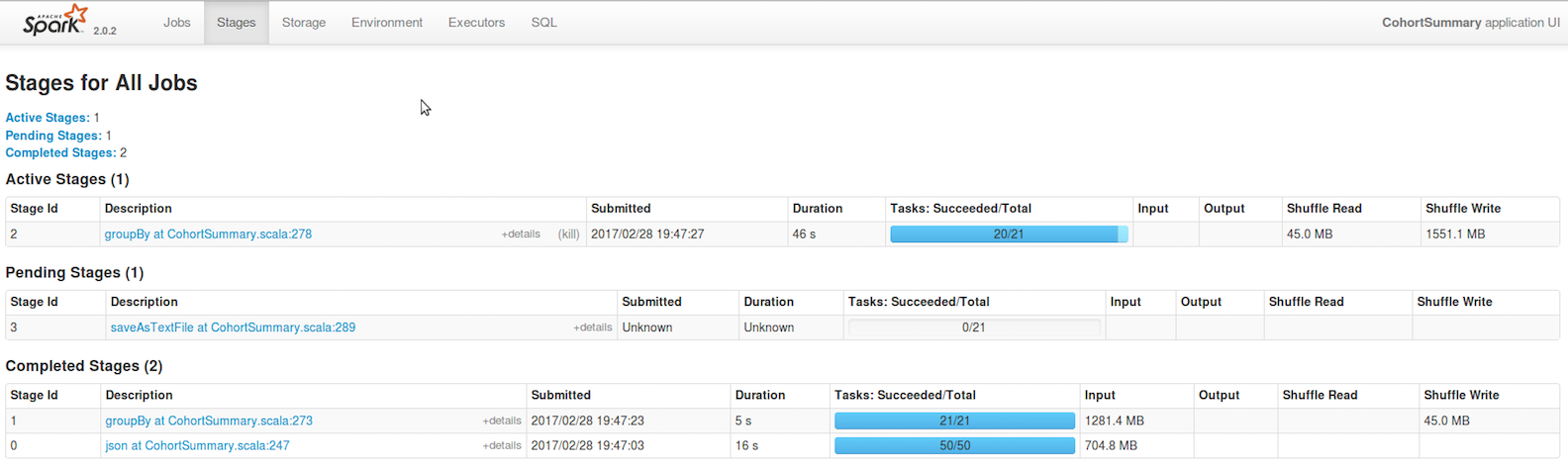
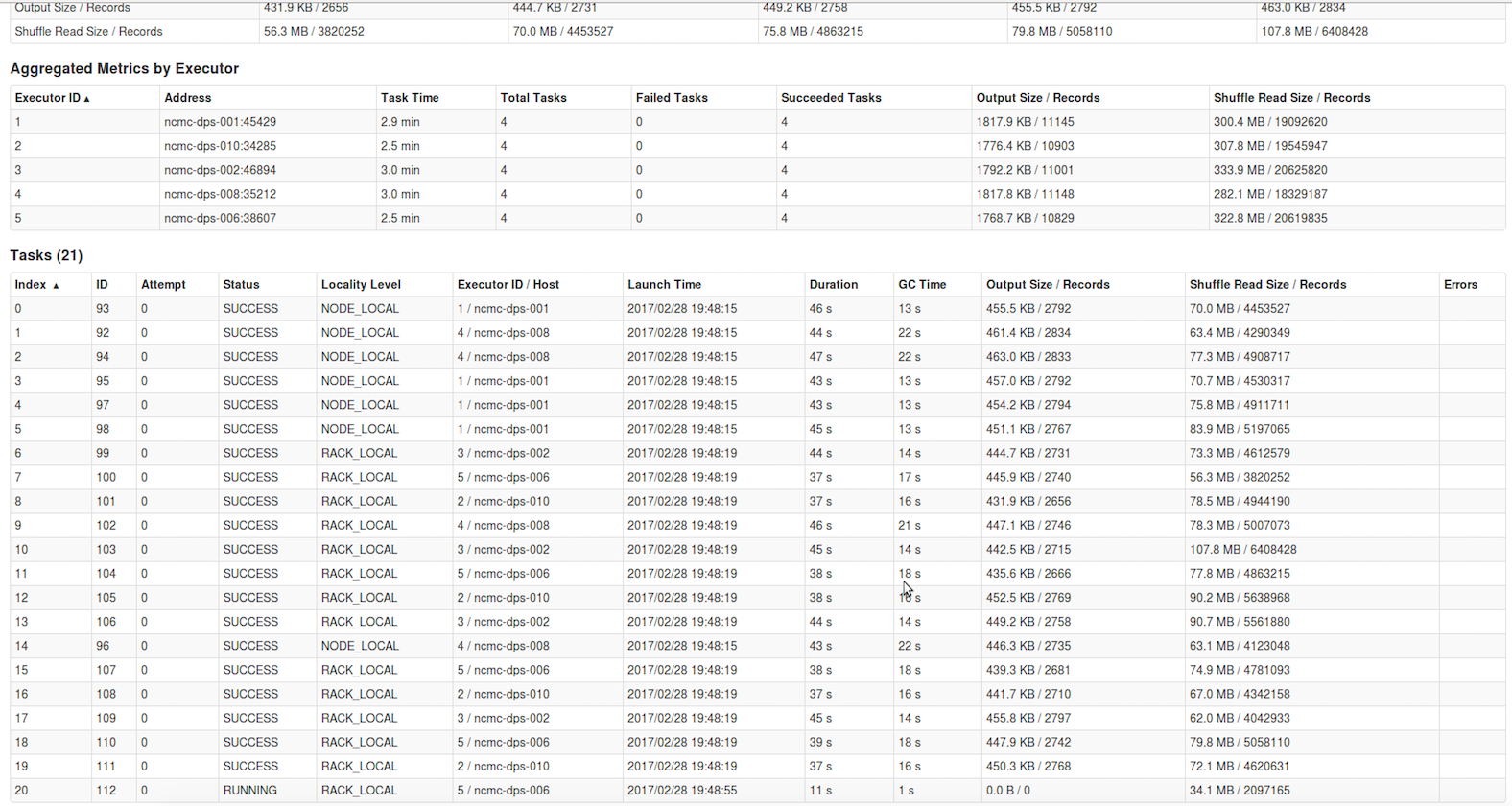
spark Task - 성능 비대칭 등 성능 이슈를 파악 할 수 있음
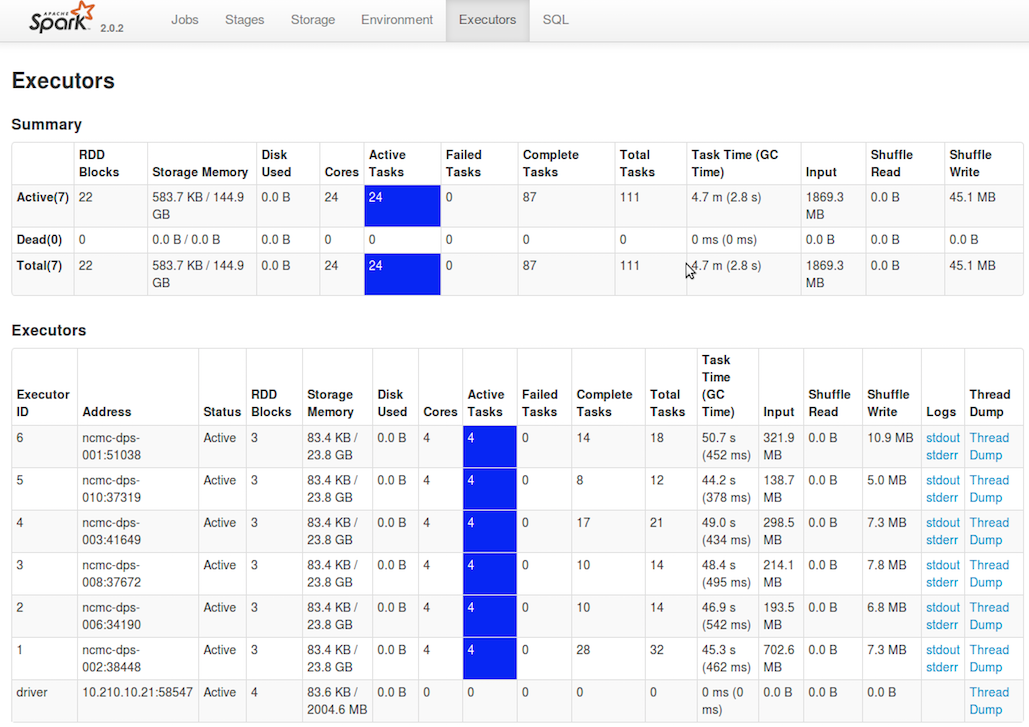
Executors
Stages DAG
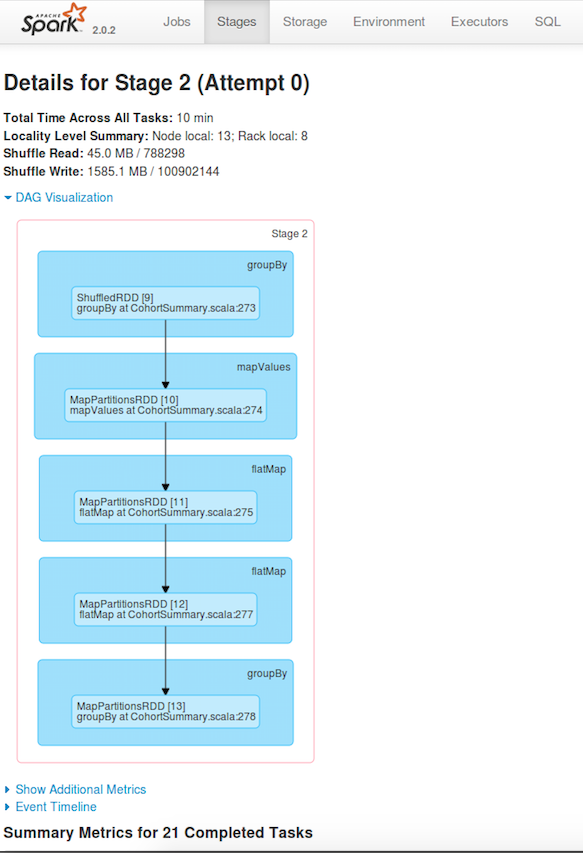
정보 찾기 -드라이버와 익스큐터로그
- 내부적인 경고 메시지나 사용자 코드에서 발생되는 예외 같은 비정상 이벤트의 상세 정보를 보유
- 단독 모드 - 애플리케이션는 마스터 웹 UI에 경로 표시 (각 작업 노드의 스파크 설치 위치의 work/)
- 메소스 - 메소스 슬레이브 노드의 work/ 경로 (마스터 UI로 확인 가능)
- 얀모드 - yarn logs -applicationId <application ID> 로 조회가능 (log4j. 설정으로 로그 레벨 수정 가능)
성능에 관한 핵심 고려 사항
병렬화 수준
- RDD는 여러개의 파티션으로 나뉘고, 각 파티션은 전체 데이터의 일부를 갖게 됨
- 스파크는 테스크를 스케줄링하여 실행 시 각 파티션당 저장된 데이터 처리할 테스크를 하나씩 만듬 (테스크당 하나의 코어 할당)
사용자 개입 없이 RDD의 병렬화 수준이 적당한지 추론 (하부의 저장 시스템에 기반하여 병렬화 수준 선택, HDFS 파일의 각 블럭당 하나의 파티션)
병렬화 개수가 너무 적으면 스파크 자원의 유휴 발생, 너무 크면 파티션의 오버헤드로 성능 이슈 발생
병렬화 수준 조정
데이터 셔플이 필요한 연산 간에 생성되는 RDD를 위한 병렬화 정도를 파라메터로 처리
이미 존재하는 RDD를 더 적거나 많게 파티션을 재배치
직렬화 포맷
spark.serializer -> org.apache.spark.serializer.KyroSerializer
spark.kyro.registrationRequired 로 엄격하게 설정가능
반드시 Serializable 인터페이스를 구현한 클래스만 가능함 (NotSerializableException 발생)
메모리 관리
하드웨어 프로비저닝