Ch 7. 클러스터에서 운영하기
참고 자료
스파크 실행 구조
- 스파크 애플리케이션 = 드라이버 + 익스큐터
- 드라이버 : 한개의 중앙 조정자(=코디네이터). 별도 자바 프로세스. main()
- 익스큐터 : 다수의 분산 작업자. 독립된 자바 프로세스.
- 클러스터 매니저 : 스파크 어플리케이션 실행
- 스파크 단독 클러스터 매니저
- 오픈소스 클러스터 매니저 : 얀, 메소스
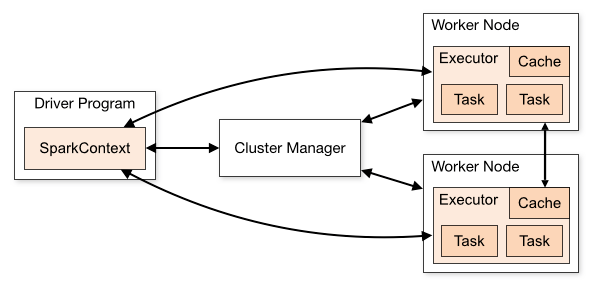
드라이버
- main() 메소드가 실행되는 프로세스. spark-shell = 드라이버
- SparkContext/RDD 생성
- Transformation/Action 실행
- 역할
- 사용자 프로그램을 태스크로 변환
- task : 하나의 노드에서 실행되는 단위 작업
- 스파크 프로그램에서 내부적으로 생성된 DAG를 물리적인 실행 계획으로 변환
- 최적화를 통해 실행 그래프를 여러개의 단계(stage)로 변환
- 각 stage는 순서에 따라 여러개의 태스크로 이루어지며, 단위 작업은 묶여서 클러스터로 전송됨
- 익스큐터에서 태스크들의 스케쥴링
- 익스큐터들의 개별 작업들을 위한 스케쥴 조정
- 사용자 프로그램을 태스크로 변환
익스큐터
태스크들을 실행하고 RDD 데이터를 저장하는 프로세스
역할
- 애플리케이션을 구성하는 작업들을 실행하여 드라이버에 결과를 되돌려줌
- 각 익스큐터 안에 존재하는 블록 매니저를 통해 사용자 프로그램에서 캐시하는 RDD 저장하기 위한 메모리 제공
클러스터 매니저
- 익스큐터를 실행하거나, 때로는 드라이버 실행(--deploy cluster)까지..
프로그램 실행하기
- spark-submit
- 클러스터 매니저 접속
- 사용자 애플리케션에 자원 조정
- spark application 실행 과정
1. spark-submit을 통해 어플리케이션 제출
2. spark-submit은 드라이버를 실행하고 사용자가 정의한 main() 호출
3. 드라이버 프로그램은 클러스터 매니저에게 익스큐터 실행을 위한 리소스 요청
4. 클러스터 매니저는 드라이버 프로그램을 대신하여 익스큐터들을 실행
5. 드라이버 프로세스가 사용자 애플리케이션을 통해 실행.
RDD의 트랜스포메이션과 액션에 기반하여 드라이버는 작업 내역을 단위 작업 형태로 나눠 익스큐터들에게 보냄
6. 단위 작업들은 결과를 계산하고 저장하기 위해 익스큐터에 의해 실행
7. 드라이버의 main()이 끝나거나 SparkContext.stop()이 호출되면 익스큐터들은 중지되고 클러스터 매니저에 사용했던 자원을 반환
spark-submit을 써서 애플리케이션 배포하기
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
- spark-submit 전달 정보
- cluster URL
- 작업에 원하는 만큼의 자원량 등을 설정하는 스케ㅔ줄링 정보
- 모든 작업 머신에 배포하기 원하는 파일이나 라이브러리 같이 애플리케이션의 실행 의존성에 대한 정보
- --class: The entry point for your application (e.g. org.apache.spark.examples.SparkPi)
- --master: The master URL for the cluster (e.g. spark://23.195.26.187:7077)
- --deploy-mode: Whether to deploy your driver on the worker nodes (cluster) or locally as an external client (client) (default: client) †
- client 모드에서는 spark-submit이 드라이버를 자신이 실행되는 머신에서 실행
- cluster 모드에서는 클러스터 작업 노드에서 실행되도록 드라이버를 전송
- --conf: Arbitrary Spark configuration property in key=value format. For values that contain spaces wrap “key=value” in quotes (as shown).
- application-jar: Path to a bundled jar including your application and all dependencies. The URL must be globally visible inside of your cluster, for instance, an hdfs:// path or a file:// path that is present on all nodes.
- application-arguments: Arguments passed to the main method of your main class, if any
Master URL Meaning
- local Run Spark locally with one worker thread (i.e. no parallelism at all).
- local[K] Run Spark locally with K worker threads (ideally, set this to the number of cores on your machine).
- local[*] Run Spark locally with as many worker threads as logical cores on your machine.
- spark://HOST:PORT Connect to the given Spark standalone cluster master. The port must be whichever one your master is configured to use, which is 7077 by default.
- mesos://HOST:PORT Connect to the given Mesos cluster. The port must be whichever one your is configured to use, which is 5050 by default. Or, for a Mesos cluster using ZooKeeper, use mesos://zk://.... To submit with --deploy-mode cluster, the HOST:PORT should be configured to connect to the MesosClusterDispatcher.
- yarn Connect to a YARN cluster in client or cluster mode depending on the value of --deploy-mode. The cluster location will be found based on the HADOOP_CONF_DIR or YARN_CONF_DIR variable.
사용자 코드와 의존성 라이브러리 패키징하기
- 간단한 의존성은 spark-submit의 --jars 플래그 이용
그 외에는 전이 의존성 그래프를 전송 -- 어플리케이션의 전체 전이 의존성 그래프를 포함하는 하나의 단일 JAR(uber JAR or assembly jar)
maven
sbt
스파크 애플리케이션 간의 스케쥴링
- 클러스터 매니저가 스파크 애플리케이션들 사이에 자원을 공유/관리해 주는 기능에 의존하여 스케쥴링한다.
클러스터 매니저
단독 클러스터 매니저
spark-submit --master spark://masternode:7077 --executor-memory 1G --total-executor-cores 8 yourapp
YARN
스파크를 얀 위에서 실행하면 원하는 데이터가 저장된 HDFS위에서 스파크가 돌아가게 되므로 유용하다.
export HADOOP_CONF_DIR = "..." // 하둡 설정 디렉토리
spark-submit --master yarn yourapp
deploy-mode
client : 애플리케이션을 제출한 머신에서 애플리케이션 드라이버 실행
- spark-shell은 사용자에게 입력을 받아야 하므로 클라이언트 모드에서만 수행
cluster : 얀 컨테이너 내부에서 실행
자원사용량 설정
| --num-executors | 어플리케이션을 수행할 익스큐터수 |
|---|---|
| --executor-memory | 각 익스큐터가 사용할 메모리 |
| --executor-cores | 얀에 요청할 코어수 |
| --queue | 작업을 수행할 큐 |
- 일부 클러스터는 익스큐터 사이즈 제한 (최대 8G)
- 고용량 익스큐터(여러개의 코어와 많은 메모리)를 적은 개수로 실행하는 것이 더 나은 성능
http://spark.apache.org/docs/latest/running-on-yarn.html
MESOS
클러스터에서 분석 워크로드나 장시간 동작 서비스 모두를 사용할 수 있게 해주는 범용 클러스터 매니저
//주키퍼를 사용하여 메소스 마스터를 고르도록 함
spark-submit --master mesos://zk://host1:2181,host2:2181,host3:2181/mesos yourapp
EC2
- 스파크에 내장된 ec2에서 클러스터를 실행 스크립트
- 여러 노드를 띄우며 단독 클러스터 매니저를 설치
- 한번 클러스터가 실행되면 단독 모드 절차에 따라 쓸 수 있다.
어떤 클러스터 매니저를 써야 할까?
- 새로 배포할 예정의 어플리케이션이라면 단독 클러스터
- 셋업이 쉽고 스파크만 돌릴 경우 다른 클러스터 매니저들이 제공하는 거의 모든 기능을 동일하게 제공
스파크를 다른 애플ㄹ리케이션과 같이 돌리고 싶거나 ㄷ좀 더 우수한 자원 스케줄링 기능을 써야 한다면(queue)
얀과 메소스로 가능하다.얀이나 단독 모드에 비해 메소스가 가지는 장점은 스파크 셸 같은 대화형 애플리이션들의 명령 실행 간에
CPU 사용량을 자동으로 낮추는 세밀한 공유 옵션이다. 이는 다양한 사용자가 대화형 셸을 사용하는 환경에서 특히 매력적이다.모든 경우에 있어서 스파크는 저장소에 빠른 접근을 위해 HDFS와 동일한 노드에 설치되는 것이 최상이다. 메소스나 단독 클러스터 매니저는 동일 노드에 수동으로 설치할 수 있으며, 대부분의 하둡 배포판은 이미 얀과 HDFS를 함께 설치하고 있다.