Ch6. 스파크 고급 프로그래밍
참고
어큐뮬레이터
결합/교환 연산을 통해 더해진 공유 변수 (클러스터에서 효과적인 병렬 처리가 가능한)
작업 노드에서 드라이버 프로그램으로 보내는 값의 집합 연산에 대해 간단한 문법을 제공 (debug task count)
scala> val accum = sc.longAccumulator("my accumulator")
accum: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 51, name: Some(my accumulator), value: 0)
scala> sc.parallelize(Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)).foreach(x => accum.add(x))
scala> accum.value
res3: Long = 55
최종 업데이트 결과를 확인하기 위해서는 반드시 액션이 실행 되어야 하며(lazy evaluation), 드라이버 프로그램에서만 확인 가능
작업 노드의 테스크는 어큐뮬레이터 value에 접근 할 수 없음 (쓰기전용)
어큐뮬레이터와 장애 내구성
- 스파크 자동적으로 오류 발생/ 딜레이 작업들을 재실행 함 (같은 작업에 대해 여러번 실행이 가능함)
- 절대적으로 신뢰할 수 있는 결과 값을 얻기 위해서는 액션 안에 어큐뮬레이터를 넣어야 함
액션이 아닌 RDD 트렌스포메이션에 사용되는 어큐뮬레이터는 정확한 결과 값을 보장 할 수 없음
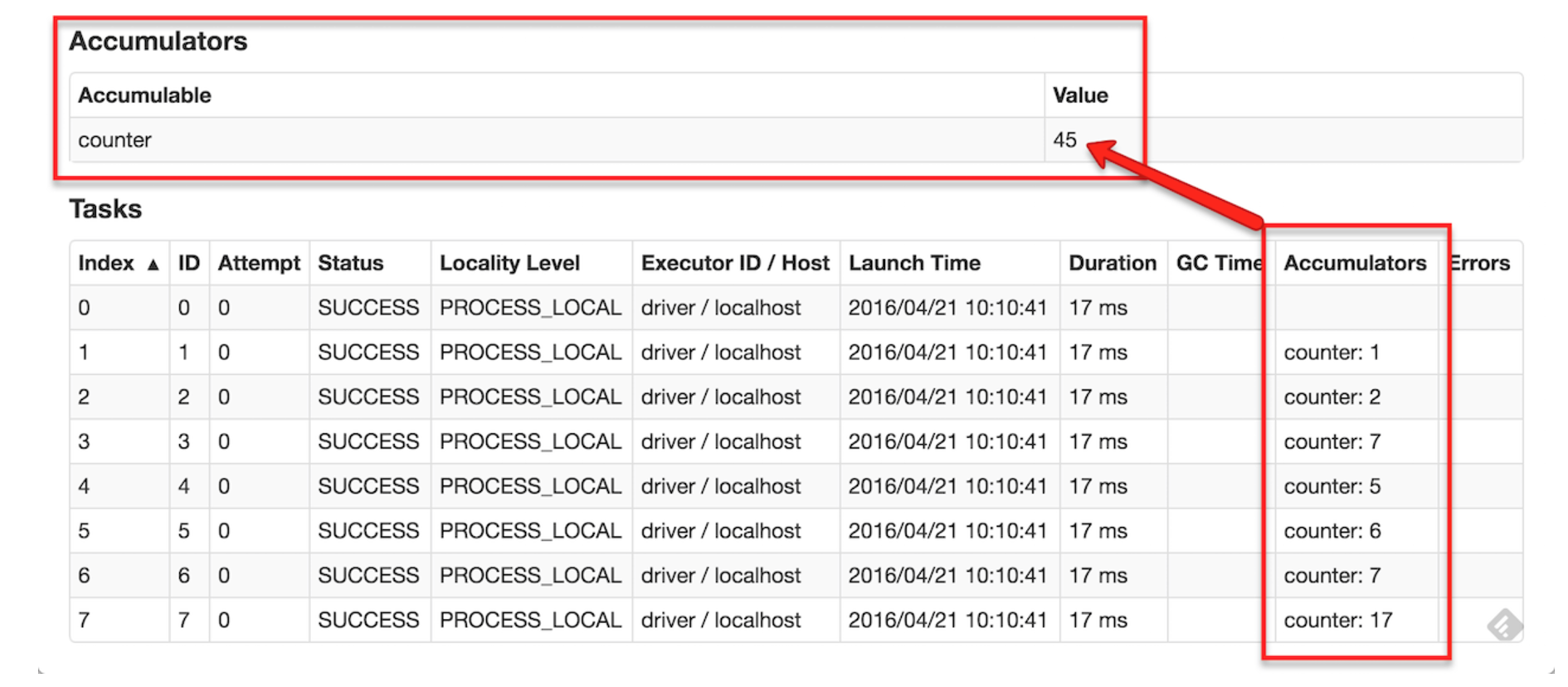
어큐뮬레이터 실행 관련 모니터링
브로드캐스트 변수
- 각 클러스터 머신에 캐싱 된 읽기 전용의 공유 변수 (큰 입력 데이터 셋을 모든 노드에 효율적으로 전달 하는)
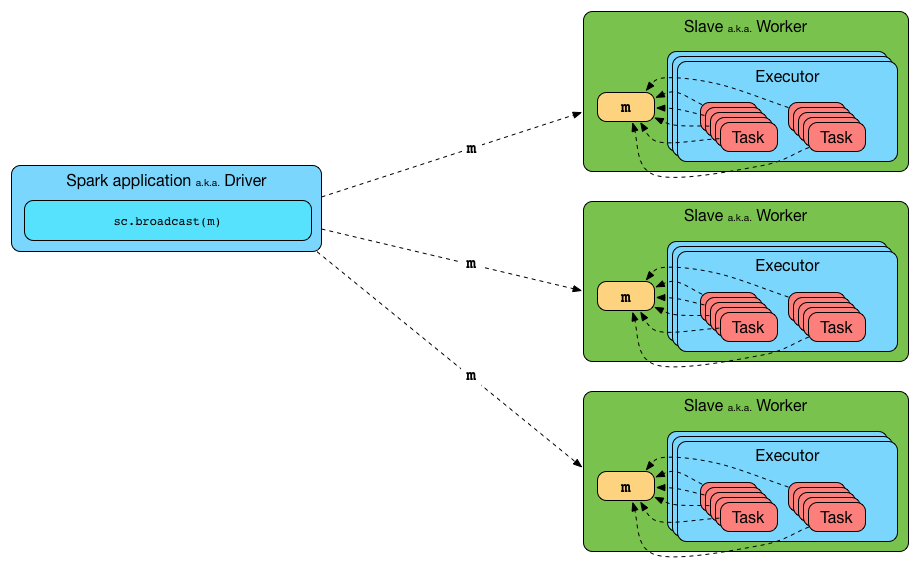
- org.apache.spark.broadcast.Broadcast[T] 타입의 객체이며(Serializable), 작업 수행 시 Broadcast 객체의 value를 통해 값에 접근
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(3)
scala> broadcastVar.value
res4: Array[Int] = Array(1, 2, 3)
scala> val map = Map("geunhee" -> "kang", "ilo" -> "lee", "dokyun" -> "kim", "sunny" -> "bang")
map: scala.collection.immutable.Map[String,String] = Map(geunhee -> kang, ilo -> lee, dokyun -> kim, sunny -> bang)
scala> val broadcastVar2 = sc.broadcast(map)
broadcastVar2: org.apache.spark.broadcast.Broadcast[scala.collection.immutable.Map[String,String]] = Broadcast(4)
scala> broadcastVar2.value.get("geunhee")
res5: Option[String] = Some(kang)
브로드캐스트 최적화를 위해 spark.serializer 속성을 통해 직렬화 라이브러리를 선택 (kyro 사용이 권장 됨)
브로드캐스트 API
| Method Name | Description |
|---|---|
| id | The unique identifier |
| value | The value |
| unpersist | Asynchronously deletes cached copies of this broadcast on the executors |
| destroy | Destroys all data and metadata related to this broadcast variable. |
파티션별로 작업하기
각 데이터 아이템에 대한 셋업 절차의 반복을 회피 (파티션 기반 버전의 map 과 foreach 를 통해 파티션 단위로 한 번만 실행 )
파티션 기반 지원 연산자

scala> def myfunc[T](iter: Iterator[T]) : Iterator[(T, T)] = {
| var res = List[(T, T)]()
| var pre = iter.next
| while (iter.hasNext)
| {
| val cur = iter.next;
| res .::= (pre, cur)
| pre = cur;
| }
| res.iterator
| }
myfunc: [T](iter: Iterator[T])Iterator[(T, T)]
scala> a.mapPartitions(myfunc).collect
res6: Array[(Int, Int)] = Array((2,3), (1,2), (5,6), (4,5), (8,9), (7,8))
외부 프로그램과 파이프로 연결하기
스칼라, 자파, 파이썬 외에 다른 언어를 파이프 메커니즘을 통해 수행 가능함
pipe() 를 통해 unix 표준 입출력 스트림을 읽고 쓸수 있음
RDD의 데이터를 stdin String 으로 읽어 트렌스포메이션으로 만들고, stdout String으로 쓰기가 가능함
pipe() 관련 주요 함수
SparkContext.addFile(path) - 파이프 연결 프로그램 경로를 전달하여 각 작업 노드에서 다운로드
SparkFiles.getRootDiretory / SparkFiles.get(filename) - pipe() 수행 시 각 작업 노드에서 프로그램을 연결해주기 위함
Numeric RDD Operation
- Spark 의 Numeric Operation 에는 RDD 모델을 생성하면서 함께 계산될 수 있는 Streaming Algorithm 이 구현 되어 있음
- RDD 의 통계정보가 함께 계산되며, stats() 함수를 통해 StatsCounter 라는 객체로 반환 됨
- StatsCounter 제공 API
- count()
- mean()
- sum()
- max()
- min()
- variance()
- sampleVariance()
- stdev()
- sampleStdev()