Ch10. 스파크 스트리밍
참고
- Spark lastest : http://spark.apache.org/docs/latest/streaming-programming-guide.html
- Spark 1.6.3 : http://spark.apache.org/docs/1.6.3/streaming-programming-guide.html
- 블로그 : http://tomining.tistory.com/92
- SKP 기술 블로그 : https://readme.skplanet.com/?p=12465
아키텍처

- 스파크 스트림은 Micro-batch라는 아키텍처를 사용 : 작은 배치의 연속
- 입력 배치는 RDD의 형태. 스파크 작업을 사용하여 다른 RDD를 생성하도록 처리
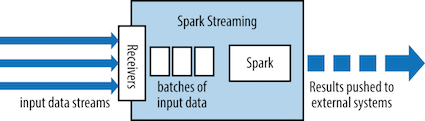
- DStream(Discretized stream, 이산 스트림) : 시간별로 도착한 데이터(RDD)의 연속적인 모음
 

(*) 각 사각형이 하나의 RDD
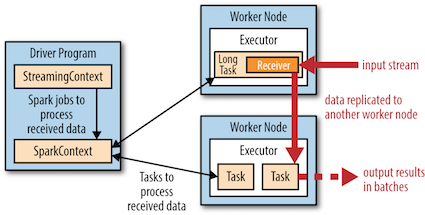
(*) 스파크 컴포넌트 내에서 스트리밍의 실행
- 각 입력 소스마다 스파크 스트리밍은 리시버(receiver)를 실행 : 애플리케이션의 익스큐터 안에서 데이터를 모으고 RDD에 저장하는 테스크
- 장애 대응을 위해 다른 익스큐터에 복제(기본 2개 노드). 가계도에 의해 재연산이 이뤄져야할 경우 비용이 크므로 체크포인팅(checkpointing)이라는 메커니즘을 따로 가지고 있음 (hdfs등에 저장). 보통 5~10개 배치 묶음마다 설정.
- 예) ssc.checkpoint("hdfs://...")
- 드라이버의 StreamingContext는 이 데이터들을 처리하기 위해 주기적으로 스파크 작업을 실행하고 이전 시간 단계의 RDD와 연결
예제
"ERROR"를 포함하는 라인만 출력하기 위한 스트리밍
source
메세지 전송
~/usr/tmp $ nc -lk 9999
ERROR hi-1
ERROR hi-2
msg
ERROR hi-3
^C
~/usr/tmp $
결과
Time: 1488962745000 ms
ERROR hi-3
UI
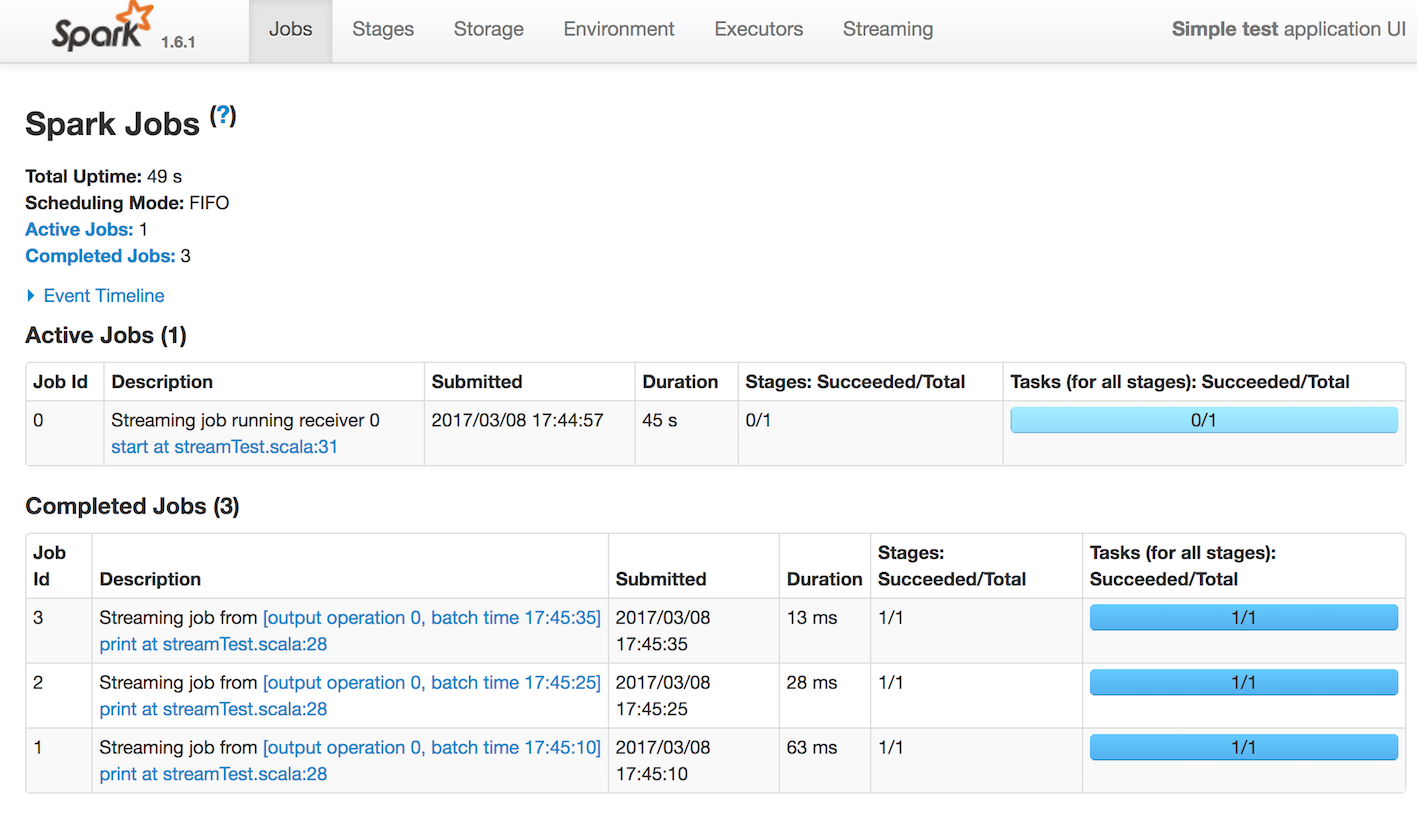 (*) print가 RDD의 액션처럼 처리
(*) print가 RDD의 액션처럼 처리
처리 흐름
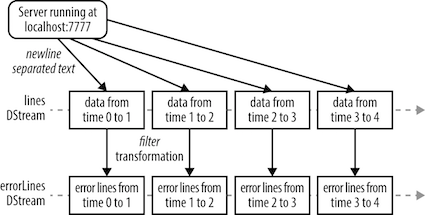
(*) DStream과 트랜스포메이션
트랜스포메이션
무상태(Stateless)와 상태 유지(Stateful)가 있음
무상태(Stateless) 트랜스포메이션
- 이전 batch 결과에 영향을 받지 않는 데이터를 처리
- map, filter, repartition, reduceByKey..
- DStream내의 모든 RDD에 각각 구분되어 적용
- 예) reduceByKey는 각 시간 단계별로 병합. 모든 데이터를 병합하는건 아님
- join, cogroup, union 등 가능
- transform 제공 : DStream rdd에 함수를 적용
- 예) val outlierDStream = accessLogsDStream.transform { rdd => extractOutliers(rdd) }
// Example Apache log line:
// 127.0.0.1 - - \[21/Jul/2014:9:55:27 -0800\] "GET /home.html HTTP/1.1" 200 2048
val ssc = new StreamingContext\(conf, opts.getWindowDuration\(\)\)
val logData = ssc.textFileStream\("/tmp/logs"\);
// map, reduce
val accessLogDStream = logData.map\(line => ApacheAccessLog.parseFromLogLine\(line\)\).cache\(\)
val ipDStream = accessLogsDStream.map\(entry => \(entry.getIpAddress\(\), 1\)\)
val ipCountsDStream = ipDStream.reduceByKey\(\(x, y\) => x + y\)
ipCountsDStream.print\(\)
// join
val ipBytesDStream = accessLogsDStream.map\(entry => \(entry.getIpAddress\(\), entry.getContentSize\(\)\)\)
val ipBytesSumDStream = ipBytesDStream.reduceByKey\(\(x, y\) => x + y\)
val ipBytesRequestCountDStream = ipRawDStream.join\(ipBytesSumDStream\)
ipBytesRequestCountDStream.print\(\)
상태 유지(Stateful) 트랜스포메이션
- 이전 batch 결과를 이용하여 데이터를 처리
- 시간 단계 범위를 넘어서 데이터를 추적하는 연산.
윈도 트랜스포메이션
- 배치 주기보다 긴 시간 간격에 대한 결과를 계산
- 윈도 시간(window duration), 슬라이딩 시간(sliding duration)을 필요로 함
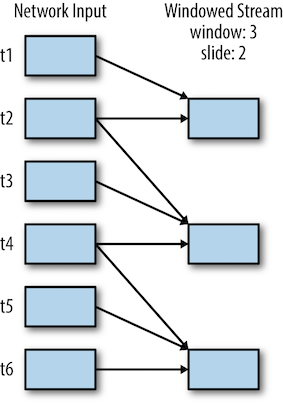
(*) 두 번의 시간 단계마다 이전 3단계에 대한 결과를 계산
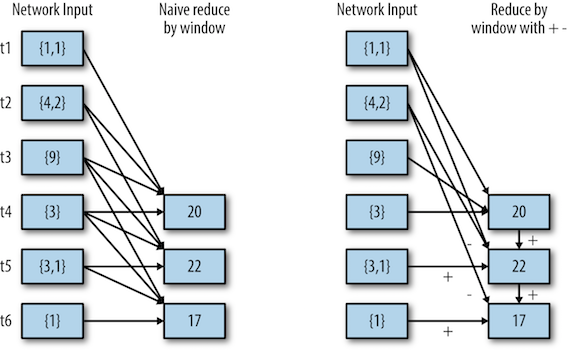
(*) 기본적인 형태의 reduceByWindow()와 역함수를 사용한 점진적인 reduceByWindows()의 차이
--> 큰 윈도에서 더 효율적으로 동작할 수 있음
updateStateByKey 트랜스포메이션
- DStream 내 여러 배치들을 하나의 state로 관리할 때. "계속 늘어나는 값" 관리할 때. 예를 들어 방문 카운트
- update(events, oldState) => newState
def updateRunningSum\(values: Seq\[Long\], state: Option\[Long\]\) = {
Some\(state.getOrElse\(0L\) + values.size\)
}
val responseCodeDStream = accessLogsDStream.map\(log => \(log.getResponseCode\(\), 1L\)\)
val responseCodeDStream = responseCodeDStream.updateStateByKey\(updateRunningSum \_\)
출력 연산
최종 데이터 처리
- print() : 디버깅 출력
- saveAsTextFiles, saveAsHadoop 등
입력 소스
Core
- 소켓 스트림 : ssc.socketTextStream
- 파일 스트림 : ssc.textFileStream(logDirectory)
- 아카 액터 스트림
Additional
아파치 카프카
- zk를 사용하는 createStream과 다이렉트로 처리하는 createDirectStream이 있음
- 성능은 createDirectStream, 하지만 offset은 직접 처리(checkpointing)
import org.apache.spark._
import org.apache.spark.SparkContext._
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
object KafkaInput {
def main\(args: Array\[String\]\) {
val Array\(zkQuorum, group, topic, numThreads\) = args
val conf = new SparkConf\(\).setAppName\("KafkaInput"\)
// Create a StreamingContext with a 1 second batch size
val ssc = new StreamingContext(conf, Seconds(1))
// Create a map of topics to number of receiver threads to use
val topics = List((topic, 1)).toMap
val topicLines = KafkaUtils.createStream(ssc, zkQuorum, group, topics)
val lines = StreamingLogInput.processLines(topicLines.map(_._2))
lines.print()
// start our streaming context and wait for it to "finish"
ssc.start()
// Wait for 10 seconds then exit. To run forever call without a timeout
ssc.awaitTermination(10000)
ssc.stop()
}
}
24/7 운영
체크포인팅
- 장애 대응을 위한 핵심 메커니즘
- hdfs나 s3를 주로 사용(하지만 성능이..)
- 목적
- 장애시 재연산이 필요한 상황을 제한. 얼마나 뒤로 돌릴지
- 드라이버 장애 시 재실행 시키고 체크포인트에서 복구하도록 요청
성능 고려 사항
배치/윈도 크기
- 500msec이 최적의 최소
- 큰 배치 크기(10초 내외)에서 점점 줄이기. 처리시간이 길어지면 거기까지
병렬화 수준
배치 처리 시간을 줄이는 일반적인 방법. 병렬화 수준을 올림(kafka의 파티션 늘리기)
- 리시버 개수 늘리기 : 여러 입력 DStream을 만들어 리시버를 추가, union을 적용해 단일 스트림으로 처리
- 받은 데이터를 명시적으로 재파티셔닝 : 리시버 늘리기 어려울 경우 DStream.reparition, union 적용
- 집합 연산 시 병렬화 개수 늘리기 : reduceByKey() 같은 함수 사용할 때 파티션 지정
가비지 컬렉션과 메모리 사용량
CMS(concurrent mark-and-sweep) Garbage Collector를 사용해 GC로 인한 스트림 처리 지연을 방지
- spark.driver.extraJavaOptions와 spark.executor.extraJavaOptions를 이용
- spark-submit --conf spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC