Ch 9. Spark SQL
- 구조화된(=Schema를 가진) 데이터 처리에 사용
Spark SQL 주요 기능
- DataFrame 추상화 클래스 제공. 이는 구조화된 데이터세트를 다루는 작업을 간편하게 만들어줌.
관계형DB의 테이블과 유사한 개념. - 다양한 구조적 포맷의 데이터를 읽고 쓸 수 있음 (ex. JSON, Hive, Parquet)
- 스파크 프로그램 내부에서나 표준 데이터베이스 연결(JDBC/ODBC)를 제공하는 외부툴 (Tableau) 같은 BI 툴 등을 써서 스파크 SQL을 통해 SQL로 데이터를 질의할 수 있다.
- DataFrame 추상화 클래스 제공. 이는 구조화된 데이터세트를 다루는 작업을 간편하게 만들어줌.
DataFrame
- Spark SQL은 DataFrame이라는 RDD확장 모델에 기반
- Row 객체들의 RDD를 가지고 있으며 Row 객체는 하나의 레코드를 표현
- 갖고 있는 레코드들의 스키마를 알고 있음
- 외부 데이터 소스, 쿼리 결과, 기존 RDD로 부터 생성 가능
스파크 SQL 라이브러리 링크
- 스파크 SQL은 하둡 SQL 엔진인 Hive를 포함하거나 포함하지 않고 빌드 가능
- Hive를 지원하는 Spark SQL
- Hive 테이블, UDF, SerDes, HiveQL 등 접근 가능
- Hive 라이브러리를 포함한다고 해서 Hive 설치가 필요한 것은 아님
- 바이너리 버전의 스파크는 Hive 지원 포함
- HiveContext
- HiveQL과 다른 Hive 기반 기능 사용 가능
- Spark 1.6 부터 Hive 1.2.1 지원
- Spark SQL을 기존 Hive 설치본에 연결하려면 hive-site.xml을 스파크의 $SPARK_HOME/conf에 카피해야 함
- Hive 지원하지 않는 SparkSQL
- SQLContext
- Spark SQL의 기능들을 제공하지만 Hive에 의존하지 않음
- SQLContext
애플리케이션에서 스파크 SQL 사용하기
- spark SQL을 사용하는 가장 강력한 방식은 스파크 애플리케이션 내부에서 사용하는 것
- 쉽게 SQL을 써서 데이터를 적재하고 쿼리를 날릴 수 있게 하면서도 파이썬, 자바, 스칼라로 작성한 일반적인 프로그램 코드와 같이 사용 가능
- Spark SQL을 사용하기 위해서는 HiveContext 또는 SQLContext를 만들어야 함
- 질의 기능 및 스파크 SQL 데이터와 연동하기 위한 추가 기능 제공
- DataFrame 만들 수 있으며, 이를 통해 SQL작업이나 map() 같은 기본 RDD 연산 수행 가능
- Spark 2.0이 되면서 SQLContext와 HiveContext가 SparkSession으로 바뀜.. (하위호환성은 보장)
// spark 1.6
import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.Row
val sqlCtx = new SQLContext(sc)
val dim = sqlCtx.read.json("/datastore/nchq/game/rk/device_id_dimension/plogdate=20161209/*")
dim.createOrReplaceTempView("dim")
val dimDf = sqlCtx.sql("select *, 'dim' as tag from dim")
// spark 2.0 or later
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
val dim = spark.read.json("/datastore/nchq/game/rk/device_id_dimension/plogdate=20161209/*")
데이터프레임
- 데이터를 읽어 들이는 것과 쿼리를 실행하는 것 모두 결과로 DataFrame을 돌려줌
- 전통적인 DB의 테이블과 비슷
- 내부적으로 하나의 DataFrame은 Row 객체들과 각 컬럼에 대한 타입 정보로 구성된 RDD를 가진다.
- Row 객체는 기본타입의 배열을 감싼 단순한 포장 객체
- registerTempTable()을 통해 임시 데이블로 등록하여 SQL query 사용 가능
- Spark 2.0에서 Dataset[Row]로 통합
- 기본 연산

데이터프레임과 RDD간의 변환
- df.rdd 를 통해 RDD에 접근 가능
- map(), filter() 등 사용 가능
- Row 객체
- DF 내부에서 레코드를 의미
- 단순히 필드들의 고정 길이 배열이다.
- Scala/Java 에서 인덱스가 주어진 필드의 값을 가져오기 위한 getter를 사용
- 표준 getter인 get(or scala의 apply)은 컬럼 번호를 받아 Object 타입(Scala에서는 Any)를 되돌려 주므로 사용자가 직접 맞는 타입으로 캐스팅
- Boolean, Byte, Double, Float, Int, Long, Short, String 타입에는 각 타입을 되돌려주는 getType() 메소드 존재
- ex. getString(0) : 0번째 필드 값을 String으로 get
캐싱
- hiveCtx.cacheTable("tableName")
- 메모리에 컬럼 지향 포맷으로 저장.
- 드라이버 프로그램이 실행되는 동안만 존재
데이터 불러오고 저장하기
아파치 하이브
- 텍스트, RC, ORC, Parquet, Avro, ProtocolBuffer 등 하이브가 지원하는 모든 타입 지원
데이터 소스/ 파케이
- Spark SQL은 연결하기 쉬운 형태의 데이터 소스 API를 지원한다.
- 스키마와 여타 다른 저장 플랫폼 타입 체계를 스파크 SQL의 데이터 모델로 자동 매핑할 수 있도록 지원
- https://spark-packages.org
- 파케이(Parquet)
- 컬럼 지향 저장 포맷이며 중첩 필드 레코드도 효과적으로 저장
JSON
scala> import org.apache.spark.sql.SQLContext
import org.apache.spark.sql.SQLContext
scala> val sqlCtx = new SQLContext(sc)
warning: there was one deprecation warning; re-run with -deprecation for details
sqlCtx: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@7a248528
scala> val twt = sqlCtx.read.json("/Users/wazupsunny/tweets.json")
17/03/06 22:10:13 WARN Utils: Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.debug.maxToStringFields' in SparkEnv.conf.
twt: org.apache.spark.sql.DataFrame = [contributorsIDs: array<string>, createdAt: string ... 15 more fields]
scala> twt.printSchema
root
|-- contributorsIDs: array (nullable = true)
| |-- element: string (containsNull = true)
|-- createdAt: string (nullable = true)
|-- currentUserRetweetId: long (nullable = true)
|-- hashtagEntities: array (nullable = true)
| |-- element: string (containsNull = true)
|-- id: long (nullable = true)
|-- inReplyToStatusId: long (nullable = true)
|-- inReplyToUserId: long (nullable = true)
|-- isFavorited: boolean (nullable = true)
|-- isPossiblySensitive: boolean (nullable = true)
|-- isTruncated: boolean (nullable = true)
|-- mediaEntities: array (nullable = true)
| |-- element: string (containsNull = true)
|-- retweetCount: long (nullable = true)
|-- source: string (nullable = true)
|-- text: string (nullable = true)
|-- urlEntities: array (nullable = true)
| |-- element: string (containsNull = true)
|-- user: struct (nullable = true)
| |-- createdAt: string (nullable = true)
| |-- description: string (nullable = true)
| |-- descriptionURLEntities: array (nullable = true)
| | |-- element: string (containsNull = true)
| |-- favouritesCount: long (nullable = true)
| |-- followersCount: long (nullable = true)
| |-- friendsCount: long (nullable = true)
| |-- id: long (nullable = true)
| |-- isContributorsEnabled: boolean (nullable = true)
| |-- isFollowRequestSent: boolean (nullable = true)
| |-- isGeoEnabled: boolean (nullable = true)
| |-- isProtected: boolean (nullable = true)
| |-- isVerified: boolean (nullable = true)
| |-- lang: string (nullable = true)
| |-- listedCount: long (nullable = true)
| |-- location: string (nullable = true)
| |-- name: string (nullable = true)
| |-- profileBackgroundColor: string (nullable = true)
| |-- profileBackgroundImageUrl: string (nullable = true)
| |-- profileBackgroundImageUrlHttps: string (nullable = true)
| |-- profileBackgroundTiled: boolean (nullable = true)
| |-- profileBannerImageUrl: string (nullable = true)
| |-- profileImageUrl: string (nullable = true)
| |-- profileImageUrlHttps: string (nullable = true)
| |-- profileLinkColor: string (nullable = true)
| |-- profileSidebarBorderColor: string (nullable = true)
| |-- profileSidebarFillColor: string (nullable = true)
| |-- profileTextColor: string (nullable = true)
| |-- profileUseBackgroundImage: boolean (nullable = true)
| |-- screenName: string (nullable = true)
| |-- showAllInlineMedia: boolean (nullable = true)
| |-- statusesCount: long (nullable = true)
| |-- translator: boolean (nullable = true)
| |-- utcOffset: long (nullable = true)
|-- userMentionEntities: array (nullable = true)
| |-- element: string (containsNull = true)
- 중첩된 필드는 '.'을 써서 접근 가능
- 배열은 '[index]'형식으로 접근 가능'
RDD에서 가져오기
- RDD로부터 데이터프레임을 만들어 낼 수도 있다.
- 스칼라에서는 케이스 클래스의 RDD가 내부적으로 DataFrame으로 변환된다.
scala> case class Person(name: String, age: Long)
defined class Person
scala> val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint]
scala> caseClassDS.show()
+----+---+
|name|age|
+----+---+
|Andy| 32|
+----+---+
JDBC/ODBC 서버
- Spark SQL은 BI 도구 등에서 스파크 클러스터에 접속하거나 클러스터를 다양한 사용자가 쓰는 것에 도움이 되도록 JDBC 기능을 제공한다.
- 단독 클러스터 프로그램으로 실행되며 여러 클라이언트에 의해 공유될 수 있다.
- Spark SQL JDBC 서버는 하이브의 HiveServer2와 연계 . Thrift 통신 프로토콜을 사용하므로 쓰리프트 서버로 알려져 있다
- Beeline 클라이언트 프로그램도 포함하고 있는데, 이것으로 JDBC 서버 접속 가능
비라인으로 작업하기
테이블을 만들고 목록을 보고 쿼리를 날려보는 Hive QL 명령어들을 실행해 볼 수 있다.
bsh-mbp:sbin wazupsunny$ ./start-thriftserver.sh --master local[*] starting org.apache.spark.sql.hive.thriftserver.HiveThriftServer2, logging to /Users/wazupsunny/Downloads/spark-2.0.2-bin-hadoop2.7/logs/spark-wazupsunny-org.apache.spark.sql.hive.thriftserver.HiveThriftServer2-1-bsh-mbp.korea.ncsoft.corp.out bsh-mbp:bin wazupsunny$ ./beeline -u jdbc:hive2://localhost:10000 Connecting to jdbc:hive2://localhost:10000 log4j:WARN No appenders could be found for logger (org.apache.hive.jdbc.Utils). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. Connected to: Spark SQL (version 2.0.2) Driver: Hive JDBC (version 1.2.1.spark2) Transaction isolation: TRANSACTION_REPEATABLE_READ Beeline version 1.2.1.spark2 by Apache Hive 0: jdbc:hive2://localhost:10000> show tables; +------------+--------------+--+ | tableName | isTemporary | +------------+--------------+--+ +------------+--------------+--+ No rows selected (0.348 seconds) 0: jdbc:hive2://localhost:10000> create table if not exists mytable(key INT, value STRING) 0: jdbc:hive2://localhost:10000> ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; +---------+--+ | Result | +---------+--+ +---------+--+ No rows selected (0.506 seconds) 0: jdbc:hive2://localhost:10000> LOAD DATA LOCAL INPATH '/Users/wazupsunny/git/learning-spark/files/int_string.csv' 0: jdbc:hive2://localhost:10000> INTO TABLE mytable; +---------+--+ | Result | +---------+--+ +---------+--+ No rows selected (0.196 seconds) 0: jdbc:hive2://localhost:10000> select * from mytable limit 10; +-------+---------+--+ | key | value | +-------+---------+--+ | NULL | NULL | | NULL | NULL | | NULL | NULL | | 1 | panda | | 2 | pandas | | 3 | pandas | +-------+---------+--+ 6 rows selected (0.251 seconds) 0: jdbc:hive2://localhost:10000> explain select * from mytable where key = 1; +------------------------------------------------------------------------------------------------------------------------------------------+--+ | plan | +------------------------------------------------------------------------------------------------------------------------------------------+--+ | == Physical Plan == *Filter (isnotnull(key#55) && (key#55 = 1)) +- HiveTableScan [key#55, value#56], MetastoreRelation default, mytable | +------------------------------------------------------------------------------------------------------------------------------------------+--+ 1 row selected (0.203 seconds)
사용자 정의 함수
스파크 SQL UDF
- 쓰고 있는 프로그래밍 언어에서 함수만 전달해서 쉽게 UDF를 등록할 수 있는 내장 메소드를 지원한다.
scala> sqlCtx.udf.register("strLenScala", (_: String).length)
res7: org.apache.spark.sql.expressions.UserDefinedFunction = UserDefinedFunction(<function1>,IntegerType,Some(List(StringType)))
scala> val tweetLength = sqlCtx.sql("SELECT strLenScala('tweet') FROM tweets LIMIT 10")
tweetLength: org.apache.spark.sql.DataFrame = [UDF(tweet): int]
하이브 UDF
Spark SQL 은 표준 Hive UDF 를 사용할 수 있다.
만약 UDF 를 직접 만들고자 한다면, UDF 클래스가 포함된 Jar 를 Spark Application 수행시 포함될 수 있도록 --jar 로 추가해 주어야 한다.
또한 Hive UDF 를 사용하기 위해서는 SparkContext 가 아니라 HiveContext 를 사용해야 한다.
hiveCtx.sql(“CREATE TEMPORARY FUNCTION name AS class.function”)
스파크 SQL 성능
- 데이터를 더 효율적으로 표현하기 위한 타입정보를 활용할 수 있다
- 데이터를 캐싱할 때 메모리 기반 칼럼 지향 저장소를 쓴다.
- 더 적은 공간을 쓸 뿐 아니라 이후의 쿼리들이 데이터의 일부만 사용한다면 스파크 SQL의 데이터 읽기 연산을 최소화해 주기도 한다.
- 조건절 하부 이동(predicate push-down) 기능은 스파크 SQL이 쿼리의 일부분을 쿼리를 수행하는 엔진의 아랫단으로 보내준다.
- 하부의 저장 시스템이 키 범위의 일부만 가져오거나 여타 다른 제한 기능을 지원한다면, 제한 조건을 데이터 저장 시스템 레벨까지 내려 보내어 수행하게 함으로써 잠재적으로 필요 없는 데이터 읽기를 많이 줄여줌
성능 최적화 옵션
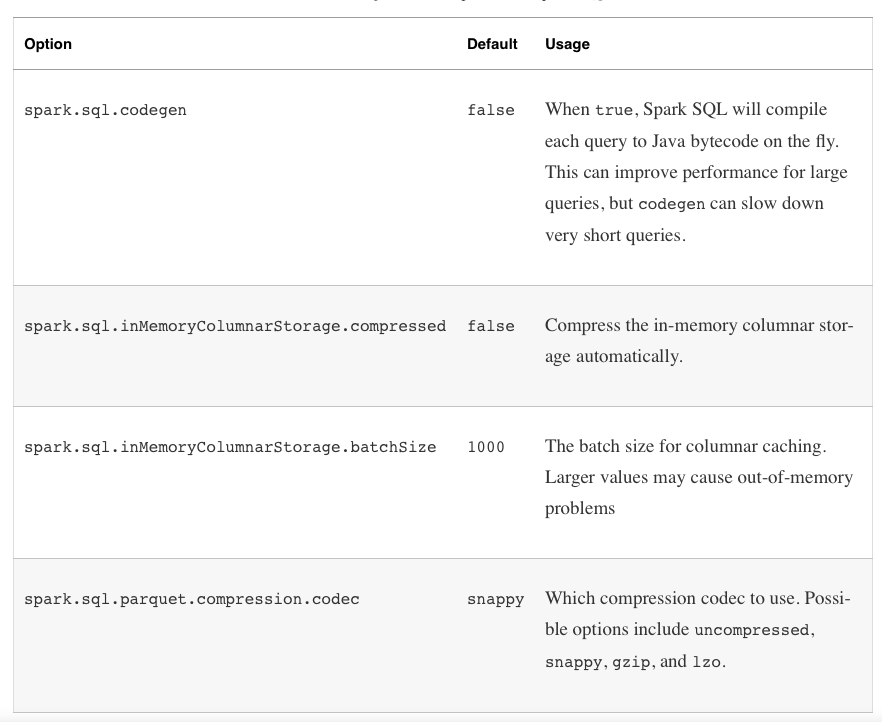
spark.sql.codegen
- 해당 속성이 true 라면 SQL 을 매번 Java Bytecode 로 변환하여 수행한다. 쿼리가 아주 길거나 자주 수행되는 쿼리에 대해서는 부분적으로 빠르지만 짧은 쿼리나 ad-hoc 쿼리 같은 경우에는 매번 SQL 을 변환해야 하기 때문에 overhead 가 있을 수 있다.
spark.sql.inMemoryColumnarStorage.batchSize
- 기본값은 1000으로 설정되어 있고, 각 Batch 마다 압축을 한다. Batch Size 가 작은 경우 압축할 용량이 작지만, 아주 큰 경우에는 메모리 상에서 압축을 하기에는 너무 클 수 있기 때문에 문제가 될 수 있다. 만약 Row 가 아주 크다면, batch size 를 줄여서 OOM 이 발생하지 않도록 해야한다. 보통은 기본 값이면 적당하다.