1. GETTING STARTED
1.1 Introduction
- LinkedIn에서 개발된 분산 스트리밍 플랫폼
- streaming platform의 세가지 주요 기능
- It lets you publish and subscribe to streams of records. In this respect it is similar to a message queue or enterprise messaging system. -- 레코드 스트림의 발행과 구독
- It lets you store streams of records in a fault-tolerant way. -- 장애시에도 처리 가능하도록 레코드 스트림 저장
- It lets you process streams of records as they occur. -- 레코드 스트림이 발생하는 대로 처리
- Kafka 사용에 적합한 예제
- 시스템이나 어플리케이션 간의 데이터 취득을 위한 실시간 데이터 파이프라인 구축
- 데이터 스트림의 변환, 대응하는 실시간 스트리밍 어플리케이션 구축
Concepts
Kafka는 1개 이상의 클러스터로 동작함
각 레코드는 키와 값, 타임스탬프로 구성되어 있음
Kafka 클러스터는 레코드의 스트림을 topic이라고 하는 카테고리에 저장함
Core APIs
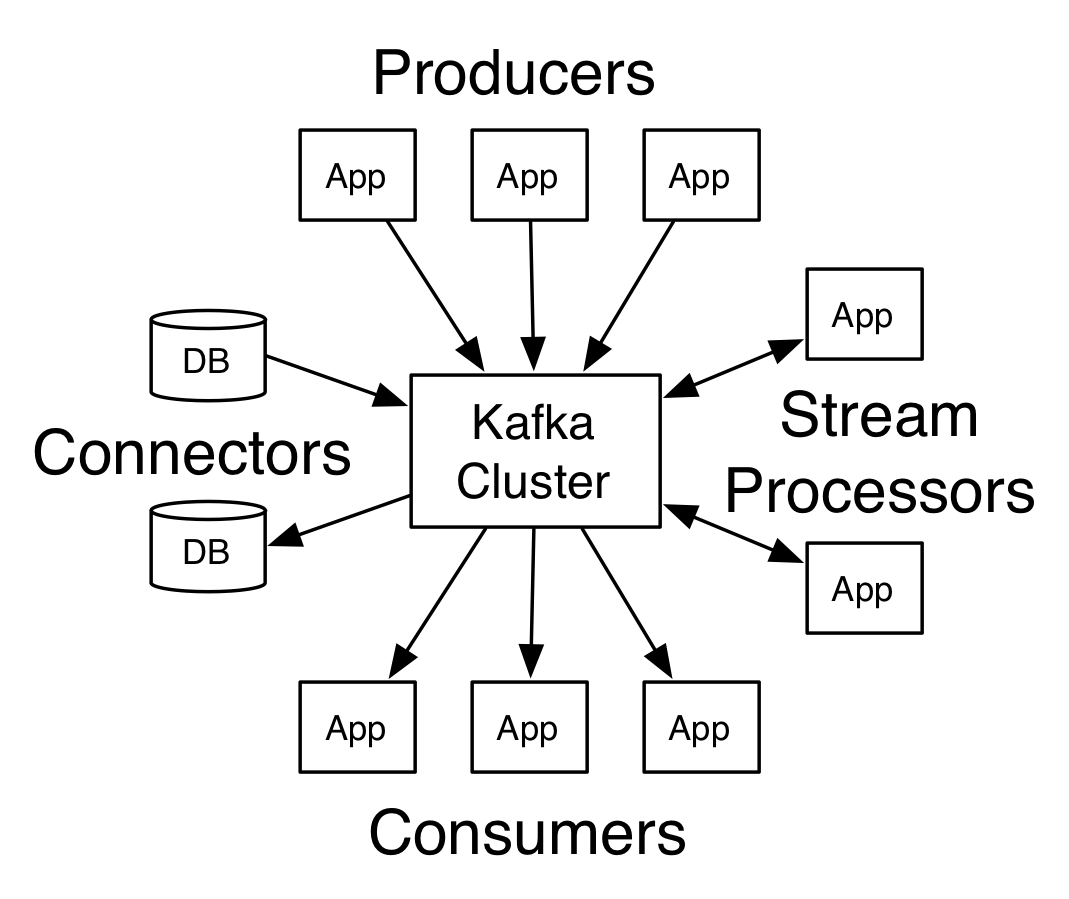
Producer API : 어플리케이션이 하나 이상의 Kafka 토픽에 레코드 스트림을 발행하도록 한다.
Consumer API : 어플리케이션이 하나 이상의 토픽을 구독하고, 생성된 레코드 스트림을 처리할 수 있다.
Streams API : 어플리케이션이 하나 이상의 토픽에서 입력 스트림을 소비하고 하나 이상의 출력 항목으로 출력 스트림을 생성하여 효과적으로 입력 스트림을 출력 스트림으로 변환하는 스트림 프로세서로 작동하도록 한다.
Connector API를 사용하면 Kafka topic을 기존 응용 프로그램 또는 데이터 시스템에 연결하는 재사용 가능한 producer 또는 consumer를 구축하고 실행할 수 있다. 예를 들어, 관계형 데이터베이스에 대한 커넥터는 테이블에 대한 모든 변경 사항을 캡처 할 수 있다.
클라이언트와 서버 간의 통신은 TCP 프로토콜을 사용
- 버전이 지정되며 이전 버전과의 하위 호환성을 유지
Topics and Logs
Topic
레코드가 발행되는 카테고리 또는 피드 이름
multi-subscriber. 즉, 주제에 기록 된 데이터를 구독하는 0, 1 또는 그 이상의 consumer가 존재
각 topic에 대해 Kafka 클러스터는 다음과 같은 파티션 로그를 유지
각 파티션은 계속해서 추가되는 정렬된 불변의 레코드 시퀀스(구조화 된 커밋 로그)입니다.
파티션의 레코드에는 파티션 내의 각 레코드를 고유하게 식별하는 offset이라는 순차적인 ID 번호가 각각 지정됩니다.
Kafka 클러스터는 구성 가능한 보존 기간을 사용하여 게시 된 모든 레코드 (소비 여부에 관계없이)를 보유합니다. 예를 들어 보존 정책을 2 일로 설정하면 레코드를 게시 한 후 2 일 동안 소비 정책을 사용할 수 있으며 그 이후에는 사용 가능한 공간을 늘리기 위해 폐기됩니다. Kafka의 성능은 데이터 크기와 관련하여 사실상 일정하므로 오래 동안 데이터를 저장하는 것은 문제가되지 않습니다.
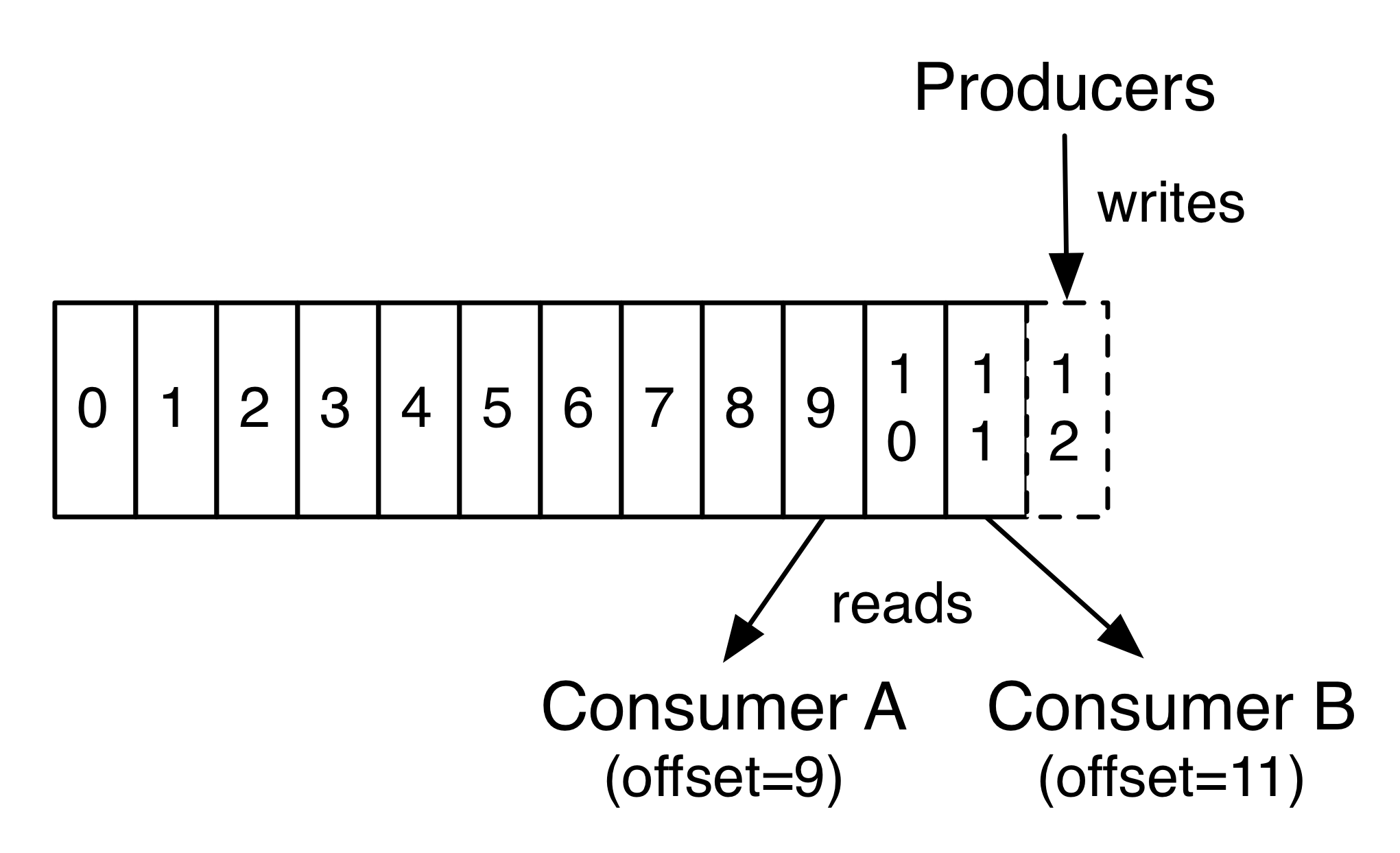
- 실제로, consumer 기준으로 유지되는 유일한 메타 데이터는 로그에서 해당 consumer의 오프셋 또는 위치입니다. 이 오프셋은 소비자가 제어합니다. 일반적으로 consumer는 레코드를 읽을 때 선형으로 오프셋을 진행하지만 실제로는 위치가 consumer에 의해 제어되므로 좋아하는 순서대로 레코드를 소비 할 수 있습니다. 예를 들어 consumer는 과거의 데이터를 다시 처리하기 위해 이전 오프셋으로 재설정하거나 가장 최근 레코드로 건너 뛰고 "지금"에서 소비하기 시작할 수 있습니다.
이러한 기능의 결합은 Kafka consumer가 매우 비용이 적다는 것을 의미합니다. 클러스터 또는 다른 consumer에게 큰 영향을 미치지 않고 오고 갈 수 있습니다. 예를 들어, 커맨드 라인 도구를 사용하여 기존 consumer가 소비 한 것을 변경하지 않고도 topic의 내용을 "tail"수 있습니다.
로그의 파티션은 여러 가지 용도로 사용됩니다. 첫째, 로그를 단일 서버에 적합한 크기 이상으로 확장 할 수 있습니다. 각 개별 파티션은 호스트하는 서버에 적합해야 하지만 주제에는 여러 파티션이 있어 임의의 양의 데이터를 처리 할 수 있습니다. 둘째, 그들은 병렬 처리의 단위처럼 행동합니다.
Distribution
로그의 파티션은 Kafka 클러스터의 서버를 통해 배포되며 각 서버는 데이터를 처리하고 파티션 공유에 대한 요청을 처리합니다. 각 파티션은 장애 허용을 위해 구성 가능한 수의 서버에 복제됩니다.
각 파티션에는 "리더" 역할을 하는 하나의 서버와 "팔로어" 역할을 하는 0 개 이상의 서버가 있습니다. 리더는 팔로워가 리더를 수동적으로 복제하는 동안 파티션에 대한 모든 읽기 및 쓰기 요청을 처리합니다. 리더가 실패하면 추종자 중 하나가 자동으로 새로운 리더가됩니다. 각 서버는 일부 파티션의 리더와 다른 서버의 팔로어로 작동하므로 클러스터 내에서 적절하게 로드 밸런싱을 이룹니다.
Producers
Producer는 선택한 topic에 데이터를 게시합니다. producer는 topic 내에서 어떤 파티션에 할당 할 레코드를 선택해야합니다. 이것은 로드밸런스를 맞추기 위해 라운드 로빈 방식으로 수행 할 수도 있고, 일부 semantic partition 함수 (레코드의 일부 키를 기반으로 함)에 따라 수행 할 수도 있습니다. 두 번째로 파티셔닝을 사용하는 방법에 대해 자세히 알아보십시오!
Consumers
소비자는 소비자 그룹 이름을 사용하여 레이블을 지정하고 주제에 게시 된 각 레코드는 구독하는 각 소비자 그룹 내의 하나의 소비자 인스턴스에 전달됩니다. 소비자 인스턴스는 별도의 프로세스 또는 별도의 시스템에있을 수 있습니다.
모든 소비자 인스턴스가 동일한 소비자 그룹을 갖는 경우 레코드는 소비자 인스턴스보다 효과적으로로드 밸런싱됩니다.
모든 소비자 인스턴스가 서로 다른 소비자 그룹을 갖고 있으면 각 레코드가 모든 소비자 프로세스에 브로드 캐스팅됩니다.
두 개의 소비자 그룹이있는 네 개의 파티션 (P0-P3)을 호스팅하는 두 대의 서버 Kafka 클러스터. 소비자 그룹 A에는 두 개의 소비자 인스턴스가 있고 그룹 B에는 네 개의 인스턴스가 있습니다.
그러나 더 일반적으로, 우리는 주제가 각각의 "논리적 가입자"에 대해 하나씩 적은 수의 소비자 그룹을 가지고 있음을 발견했습니다. 각 그룹은 확장 성 및 내결함성을위한 많은 소비자 인스턴스로 구성됩니다. 이는 구독자가 단일 프로세스 대신 소비자의 클러스터 인 게시 - 구독 의미론 이상의 것입니다.
카프카에서 소비가 구현되는 방식은 로그의 파티션을 소비자 인스턴스로 나누어 각 인스턴스가 어느 시점에서든 파티션의 "공정한 공유"를 독점적으로 사용하는 것입니다. 이 그룹 구성원을 유지 관리하는이 과정은 Kafka 프로토콜에 의해 동적으로 처리됩니다. 새 인스턴스가 그룹에 참여하면 그룹의 다른 구성원에서 일부 파티션을 인계받습니다. 인스턴스가 종료되면 해당 파티션이 나머지 인스턴스에 배포됩니다.
카프카 (Kafka)는 토픽의 다른 파티션 사이가 아닌 파티션 내의 레코드에 대해서만 전체 순서를 제공합니다. 대부분의 응용 프로그램에서는 키 단위로 데이터를 분할하는 기능과 함께 파티션 단위의 순서만으로 충분합니다. 그러나 레코드 전체 순서가 필요한 경우 이는 하나의 파티션 만있는 항목으로 수행 할 수 있습니다. 단, 이는 소비자 그룹당 하나의 소비자 프로세스를 의미합니다.
Guarantees
높은 수준의 카프카에서는 다음과 같은 보증을 제공합니다.
producer가 특정 topic 파티션으로 보낸 메시지는 전송된 순서대로 추가됩니다.
즉, 레코드 M1이 레코드 M2와 동일한 생성자에 의해 보내지고 M1이 먼저 보내지면 M1은 M2보다 더 낮은 오프셋을 가지며 로그에서 더 일찍 나타납니다.consumer 인스턴스는 로그에 저장된 순서대로 레코드를 봅니다.
복제 인수 N이있는 항목의 경우 로그에 커밋 된 레코드를 손실하지 않고 최대 N-1 개의 서버 오류를 허용합니다.
이러한 보증에 대한 자세한 내용은 설명서의 디자인 섹션에 나와 있습니다.
Kafka as a messaging system
전통적인 엔터프라이즈 메시징 시스템
- Queuing
- consumer 풀은 서버에서 읽을 수 있으며 각 레코드는 그 중 하나에 저장
- 장점 : 여러 소비자 인스턴스에서 데이터 처리를 나눌 수 있으므로 처리 규모를 확장 할 수 있다
- 단점 : multi-subscriber가 아님 (하나의 프로세스가 데이터를 읽으면 사라짐)
- publish-subscribe
- 장점 : 레코드는 여러 소비자에게 브로드 캐스팅 가능
- 단점 : 모든 메시지가 모든 구독자에게 전달되기 때문에 확장 처리 방법이 없음
The Consumer group concept in Kafka
위 두 개념을 일반화
- Queuing에서와 마찬가지로 소비자 그룹은 프로세스 모음 (consumer 그룹의 구성원)을 통해 처리를 나눌 수 있다.
- publish-subscribe와 마찬가지로 Kafka를 사용하면 여러 consumer 그룹에 메시지를 브로드 캐스트 할 수 있다.
장점
모든 topic이 이러한 속성을 모두 갖고 있음.
scale processing & multi-subscriber
전통적인 메시징 시스템보다 강력하게 순서를 보장
- 카프카는 더 잘합니다. 주제 내에서 병렬 처리 개념 (파티션)을 가짐으로써 카프카는 소비자 프로세스 풀에 대해 순서 보장과 로드 밸런싱을 모두 제공 할 수 있습니다. 이는 주제의 파티션을 소비자 그룹의 소비자에 할당하여 각 파티션이 그룹의 정확히 한 소비자에 의해 소비되도록하여 수행됩니다. 이렇게하면 소비자가 해당 파티션의 유일한 독자이고 순서대로 데이터를 사용하게됩니다. 파티션이 많으므로 많은 소비자 인스턴스에서로드의 균형을 유지합니다. 그러나 소비자 그룹에는 파티션보다 더 많은 소비자 인스턴스가있을 수 없습니다.
- 전통적인 큐는 서버에서 순서대로 레코드를 보유하고, 여러 소비자가 큐에서 소모하는 경우 서버는 저장된 순서대로 레코드를 전달합니다. 그러나 서버가 레코드를 순서대로 전달하더라도 레코드는 비동기 적으로 소비자에게 전달되므로 서로 다른 소비자에게 순서가 잘못 될 수 있습니다. 즉, 병렬 소비가 발생하면 레코드의 순서가 손실됩니다. 메시징 시스템은 대기열에서 하나의 프로세스 만 사용할 수있는 "독점적 인 소비자"라는 개념을 사용하여이 문제를 해결하기도하지만 처리 과정에서 병렬 처리가 없다는 것을 의미합니다.
Kafka as a Storage System
메시지를 소비하는 것과 별개로 발행하도록 하는 메시지 큐는 사실상 동작중인 메시지의 스토리지 시스템으로 작동한다.
Kafka에 기록 된 데이터는 디스크에 기록되고 내결함성을 위해 복제됩니다. Kafka는 생산자가 서면 승인을 기다릴 수 있도록 하여 서면이 완전히 복제되고 서면으로 작성된 서 v가 지속되는 경우에도 서 v가 지속될 때까지 쓰기가 완료된 것으로 간주하지 않도록합니다.
Kafka가 scale well-Kafka를 사용하는 디스크 구조는 서버에 50KB 또는 50TB의 영구 데이터를 가지고 있더라도 동일하게 수행합니다.
스토리지를 중요하게 생각하고 클라이언트가 읽기 위치를 제어 할 수있게 된 결과 Kafka는 성능이 좋고 대기 시간이 짧은 커밋 로그 저장, 복제 및 전파 전용으로 사용되는 일종의 특수 목적 분산 파일 시스템으로 생각할 수 있습니다.
Kafka for Streaming Processing
데이터 스트림을 읽고, 쓰고, 저장하는 것만으로는 충분하지 않습니다. 목적은 스트림의 실시간 처리를 가능하게하는 것입니다.
Kafka의 Stream Processor는 input topic에서 연속적인 데이터 스트림을 취하여 입력에 대한 처리를 수행하고, output topic에 지속적인 데이터 스트림을 생성
생산자 API와 소비자 API를 사용하여 직접 간단한 처리를 수행 할 수 있습니다. 그러나보다 복잡한 변환의 경우 Kafka는 완전히 통합 된 Streams API를 제공합니다. 따라서 스트림에서 집계를 계산하거나 스트림을 함께 결합하는 중요하지 않은 처리를하는 응용 프로그램을 작성할 수 있습니다.
스트림 API는 Kafka가 제공하는 핵심 기본 요소를 기반으로합니다. 입력에 생성자 및 소비자 API를 사용하고, 상태 저장을 위해 Kafka를 사용하고, 스트림 프로세서 인스턴스간에 내결함성을 위해 동일한 그룹 메커니즘을 사용합니다.
Putting the pieces together
메시징, 스토리지 및 스트림 처리의 이러한 결합은 드문 것처럼 보일 수 있지만 스트리밍 플랫폼으로서의 카프카의 역할에 필수적입니다.
HDFS와 같은 분산 파일 시스템을 사용하면 일괄 처리를 위해 정적 파일을 저장할 수 있습니다. 사실상 이와 같은 시스템을 사용하면 과거의 기록 데이터를 저장하고 처리 할 수 있습니다.
기존 엔터프라이즈 메시징 시스템을 사용하면 가입 한 후에 도착할 향후 메시지를 처리 할 수 있습니다. 이러한 방식으로 구축 된 응용 프로그램은 도착하는대로 미래의 데이터를 처리합니다.
Kafka는이 두 가지 기능을 모두 갖추고 있으며 스트리밍 응용 프로그램 및 스트리밍 데이터 파이프 라인 용 플랫폼으로 Kafka를 사용하는 데있어이 두 가지 기능이 모두 중요합니다.
스토리지 및 대기 시간이 짧은 구독을 결합하여 스트리밍 응용 프로그램은 과거 및 미래 데이터를 동일한 방식으로 처리 할 수 있습니다. 즉, 단일 응용 프로그램에서 기록 된 저장된 데이터를 처리 할 수 있지만 마지막 레코드에 도달 할 때 종료하는 것이 아니라 향후 데이터가 도착할 때 처리를 유지할 수 있습니다. 이는 메시지 처리 응용 프로그램뿐만 아니라 일괄 처리를 포함하는 스트림 처리의 일반화 된 개념입니다.
마찬가지로 스트리밍 데이터 파이프 라인의 경우 실시간 이벤트에 가입하면 매우 짧은 지연 시간의 파이프 라인에 Kafka를 사용할 수 있습니다. 데이터를 안정적으로 저장하는 기능을 사용하면 데이터 전송을 보장해야하는 중요한 데이터 또는 정기적으로 데이터를로드하거나 유지 관리를 위해 오랜 기간 동안 데이터를 다운로드하는 오프라인 시스템과의 통합에이 데이터를 사용할 수 있습니다. 스트림 처리 설비는 도착하는대로 데이터를 변환 할 수있게합니다.
Kafka가 제공하는 보증, API 및 기능에 대한 자세한 내용은 나머지 설명서를 참조하십시오.
1.2 Use Cases
Messaging
Message broker 사용 예
- 데이터 생성자에서 처리를 분리, 처리되지 않은 메시지를 버퍼링
Kafka는 뛰어난 처리량, 기본 제공 파티셔닝, 복제 및 내결함성을 갖추고 있어 대규모 메시지 처리 응용 프로그램에 적합
Website Activity Tracking
Kafka의 원래의 사용 사례는 사용자 활동 추적 파이프 라인을 실시간 publish - subscribe 피드 집합으로 재구성 할 수 있어야했습니다.
이는 사이트 활동 (페이지 조회수, 검색 또는 사용자가 취할 수있는 기타 작업)이 활동 유형별로 하나의 주제와 함께 중앙 주제에 게시됨을 의미합니다.
이 피드는 실시간 처리, 실시간 모니터링, 오프라인 처리 및보고를위한 Hadoop 또는 오프라인 데이터웨어 하우징 시스템으로의 로드를 포함하여 다양한 사용 사례에 대한 구독에 사용할 수 있습니다.
각 사용자 페이지 뷰에 대해 많은 활동 메시지가 생성되므로 활동 추적은 대개 매우 높은 볼륨입니다.
Metrics
Kafka는 종종 운영 모니터링 데이터로 사용됩니다.
여기에는 분산 응용 프로그램의 통계를 집계하여 운영 데이터의 중앙 집중식 피드를 생성하는 작업이 포함됩니다.
Log Aggregation
로그 집계는 일반적으로 물리적 인 로그 파일을 서버에서 수집하여 처리를 위해 중앙 위치 (파일 서버 또는 HDFS 등)에 배치합니다.
Kafka는 파일의 세부 사항을 추상화하여 로그 또는 이벤트 데이터를 메시지 스트림으로보다 깔끔하게 추상화합니다.
이를 통해 대기 시간이 더 낮은 처리가 가능하며 여러 데이터 소스 및 분산 된 데이터 소비를보다 쉽게 지원할 수 있습니다.
Scribe 또는 Flume과 같은 로그 중심 시스템과 비교하여 카프카는 성능이 우수하고 복제로 인해 내구성이 강화되었으며 엔드 투 엔드 대기 시간이 훨씬 낮습니다.
Stream Processing
Kafka의 많은 사용자는 여러 단계로 구성된 처리 파이프 라인에서 데이터를 처리합니다. 여기에서는 원시 입력 데이터가 카프카 항목에서 소비 된 다음 추가 소비 또는 후속 처리를 위해 새로운 주제로 집계, 강화 또는 변환됩니다.
예를 들어, 뉴스 기사를 추천하는 처리 파이프 라인은 RSS 피드의 기사 내용을 크롤링하여 "기사"주제에 게시 할 수 있습니다.
추가 처리로이 컨텐츠를 정규화 또는 중복 제거하고 정리 된 기사 컨텐츠를 새 주제에 게시 할 수 있습니다.
최종 처리 단계에서이 내용을 사용자에게 권장하려고 시도 할 수 있습니다.
이러한 프로세싱 파이프 라인은 개별 주제를 기반으로 실시간 데이터 흐름의 그래프를 생성합니다.
0.10.0.0부터 시작하여 가볍지 만 강력한 스트림 처리 라이브러리 Kafka Streams는 Apache Kafka에서 위에서 설명한 데이터 처리를 수행 할 수 있습니다.
Kafka Streams 외에도 다른 오픈 소스 스트림 처리 도구에는 Apache Storm과 Apache Samza가 있습니다.
Event Sourcing
이벤트 소싱은 상태 변경이 시간 순서로 기록 된 레코드 순서로 기록되는 응용 프로그램 디자인 스타일입니다.
매우 큰 저장된 로그 데이터에 대한 Kafka의 지원은이 스타일로 구축 된 응용 프로그램을위한 훌륭한 백엔드입니다.
Commit Log
Kafka는 분산 시스템에 대한 일종의 외부 커밋 로그 역할을 할 수 있습니다.
이 로그는 노드간에 데이터를 복제하는 데 도움을 주며 장애가 발생한 노드가 데이터를 복원 할 수있는 재 동기화 메커니즘 역할을합니다.
Kafka의 로그 압축 기능은이 사용법을 지원합니다. 이 사용법에서 Kafka는 Apache BookKeeper 프로젝트와 유사합니다.
1.3 Quick Start
Step 1: Download the code
Step 2: Start the server
start zookeeper server
[wazupsunny@MBP kafka_2.11-0.10.2.0]$ bin/zookeeper-server-start.sh config/zookeeper.properties
[2017-03-20 00:49:43,529] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
[2017-03-20 00:49:43,532] INFO autopurge.snapRetainCount set to 3 (org.apache.zookeeper.server.DatadirCleanupManager)
[2017-03-20 00:49:43,532] INFO autopurge.purgeInterval set to 0 (org.apache.zookeeper.server.DatadirCleanupManager)
[2017-03-20 00:49:43,532] INFO Purge task is not scheduled. (org.apache.zookeeper.server.DatadirCleanupManager)
[2017-03-20 00:49:43,532] WARN Either no config or no quorum defined in config, running in standalone mode (org.apache.zookeeper.server.quorum.QuorumPeerMain)
[2017-03-20 00:49:43,554] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
[2017-03-20 00:49:43,555] INFO Starting server (org.apache.zookeeper.server.ZooKeeperServerMain)
...
start Kafka server
[wazupsunny@MBP kafka_2.11-0.10.2.0]$ bin/kafka-server-start.sh config/server.properties
[2017-03-20 00:50:08,144] INFO KafkaConfig values:
advertised.host.name = null
advertised.listeners = null
advertised.port = null
authorizer.class.name =
auto.create.topics.enable = true
auto.leader.rebalance.enable = true
background.threads = 10
broker.id = 0
broker.id.generation.enable = true
broker.rack = null
compression.type = producer
connections.max.idle.ms = 600000
controlled.shutdown.enable = true
controlled.shutdown.max.retries = 3
controlled.shutdown.retry.backoff.ms = 5000
controller.socket.timeout.ms = 30000
create.topic.policy.class.name = null
default.replication.factor = 1
delete.topic.enable = false
fetch.purgatory.purge.interval.requests = 1000
group.max.session.timeout.ms = 300000
group.min.session.timeout.ms = 6000
host.name =
inter.broker.listener.name = null
inter.broker.protocol.version = 0.10.2-IV0
leader.imbalance.check.interval.seconds = 300
leader.imbalance.per.broker.percentage = 10
listener.security.protocol.map = SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,TRACE:TRACE,SASL_SSL:SASL_SSL,PLAINTEXT:PLAINTEXT
listeners = null
log.cleaner.backoff.ms = 15000
log.cleaner.dedupe.buffer.size = 134217728
log.cleaner.delete.retention.ms = 86400000
log.cleaner.enable = true
log.cleaner.io.buffer.load.factor = 0.9
log.cleaner.io.buffer.size = 524288
log.cleaner.io.max.bytes.per.second = 1.7976931348623157E308
log.cleaner.min.cleanable.ratio = 0.5
log.cleaner.min.compaction.lag.ms = 0
log.cleaner.threads = 1
log.cleanup.policy = [delete]
log.dir = /tmp/kafka-logs
log.dirs = /tmp/kafka-logs
log.flush.interval.messages = 9223372036854775807
log.flush.interval.ms = null
log.flush.offset.checkpoint.interval.ms = 60000
log.flush.scheduler.interval.ms = 9223372036854775807
log.index.interval.bytes = 4096
log.index.size.max.bytes = 10485760
log.message.format.version = 0.10.2-IV0
log.message.timestamp.difference.max.ms = 9223372036854775807
log.message.timestamp.type = CreateTime
log.preallocate = false
log.retention.bytes = -1
log.retention.check.interval.ms = 300000
log.retention.hours = 168
log.retention.minutes = null
log.retention.ms = null
log.roll.hours = 168
log.roll.jitter.hours = 0
log.roll.jitter.ms = null
log.roll.ms = null
log.segment.bytes = 1073741824
log.segment.delete.delay.ms = 60000
max.connections.per.ip = 2147483647
max.connections.per.ip.overrides =
message.max.bytes = 1000012
metric.reporters = []
metrics.num.samples = 2
metrics.recording.level = INFO
metrics.sample.window.ms = 30000
min.insync.replicas = 1
num.io.threads = 8
num.network.threads = 3
num.partitions = 1
num.recovery.threads.per.data.dir = 1
num.replica.fetchers = 1
offset.metadata.max.bytes = 4096
offsets.commit.required.acks = -1
offsets.commit.timeout.ms = 5000
offsets.load.buffer.size = 5242880
offsets.retention.check.interval.ms = 600000
offsets.retention.minutes = 1440
offsets.topic.compression.codec = 0
offsets.topic.num.partitions = 50
offsets.topic.replication.factor = 3
offsets.topic.segment.bytes = 104857600
port = 9092
principal.builder.class = class org.apache.kafka.common.security.auth.DefaultPrincipalBuilder
producer.purgatory.purge.interval.requests = 1000
queued.max.requests = 500
quota.consumer.default = 9223372036854775807
quota.producer.default = 9223372036854775807
quota.window.num = 11
quota.window.size.seconds = 1
replica.fetch.backoff.ms = 1000
replica.fetch.max.bytes = 1048576
replica.fetch.min.bytes = 1
replica.fetch.response.max.bytes = 10485760
replica.fetch.wait.max.ms = 500
replica.high.watermark.checkpoint.interval.ms = 5000
replica.lag.time.max.ms = 10000
replica.socket.receive.buffer.bytes = 65536
replica.socket.timeout.ms = 30000
replication.quota.window.num = 11
replication.quota.window.size.seconds = 1
request.timeout.ms = 30000
reserved.broker.max.id = 1000
sasl.enabled.mechanisms = [GSSAPI]
sasl.kerberos.kinit.cmd = /usr/bin/kinit
sasl.kerberos.min.time.before.relogin = 60000
sasl.kerberos.principal.to.local.rules = [DEFAULT]
sasl.kerberos.service.name = null
sasl.kerberos.ticket.renew.jitter = 0.05
sasl.kerberos.ticket.renew.window.factor = 0.8
sasl.mechanism.inter.broker.protocol = GSSAPI
security.inter.broker.protocol = PLAINTEXT
socket.receive.buffer.bytes = 102400
socket.request.max.bytes = 104857600
socket.send.buffer.bytes = 102400
ssl.cipher.suites = null
ssl.client.auth = none
ssl.enabled.protocols = [TLSv1.2, TLSv1.1, TLSv1]
ssl.endpoint.identification.algorithm = null
ssl.key.password = null
ssl.keymanager.algorithm = SunX509
ssl.keystore.location = null
ssl.keystore.password = null
ssl.keystore.type = JKS
ssl.protocol = TLS
ssl.provider = null
ssl.secure.random.implementation = null
ssl.trustmanager.algorithm = PKIX
ssl.truststore.location = null
ssl.truststore.password = null
ssl.truststore.type = JKS
unclean.leader.election.enable = true
zookeeper.connect = localhost:2181
zookeeper.connection.timeout.ms = 6000
zookeeper.session.timeout.ms = 6000
zookeeper.set.acl = false
zookeeper.sync.time.ms = 2000
(kafka.server.KafkaConfig)
[2017-03-20 00:50:08,194] INFO starting (kafka.server.KafkaServer)
[2017-03-20 00:50:08,197] INFO Connecting to zookeeper on localhost:2181 (kafka.server.KafkaServer)
[2017-03-20 00:50:08,212] INFO Starting ZkClient event thread. (org.I0Itec.zkclient.ZkEventThread)
Step 3: create a topic
// create a topic
[wazupsunny@MBP kafka_2.11-0.10.2.0]$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
Created topic "test".
// see the topic what we made
[wazupsunny@MBP kafka_2.11-0.10.2.0]$ bin/kafka-topics.sh --list --zookeeper localhost:2181
test
Step 4: Send some messages
[wazupsunny@MBP kafka_2.11-0.10.2.0]$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
This is a message
This is another message
Step 5: start a consumer
[wazupsunny@MBP kafka_2.11-0.10.2.0]$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
This is a message
This is another message
Step 6: setting up a multi-broker broker
너무 길어서 ... https://kafka.apache.org/documentation/#quickstart_multibroker
// not work
[wazupsunny@MBP kafka_2.11-0.10.2.0]$ bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic my-replicated-topic
// but producer is work
[wazupsunny@MBP kafka_2.11-0.10.2.0]$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
producer restart
// consumer received topic
[wazupsunny@MBP kafka_2.11-0.10.2.0]$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic
producer restart
// fault-tolerance test
// 1. Kill server
// 2. producer publish message
[wazupsunny@MBP kafka_2.11-0.10.2.0]$ bin/kafka-console-producer.sh --broker-list localhost:9092 --topic my-replicated-topic
...
message after server die
kkk
// 3. consumer still receives message
[wazupsunny@MBP kafka_2.11-0.10.2.0]$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic
...
message after server die
kkk
Step 7: Use Kafka connect to import/export data
1.4 Ecosystem
1.5 Upgrading