4. Design
4.1 Motivation
실시간 데이터 처리를 위한 통합 플랫폼
- high-throughput
- deal with large data backlogs
- low-latency
- partitioned, distributed, real-time processing --> partitioning, consumer model
4.2 Persistence
Don't fear the filesystem!
메세지를 직접 메모리에 캐싱하지 않고 파일 시스템 페이지 캐시를 사용
- JVM 메모리 오버헤드 최소화(GC)
- 커널의 페이지 캐시가 디스크로 저장
Constant Time Suffices
- 영구 큐(Persistent queue)는 모든 연산이 O(1)이고 읽기, 쓰기가 서로 간섭하지 않음
- 성능이 데이터 크기와 관련 없는 장점
- 메세지 사용시 바로 삭제하지 않고 오랜기간 보관. Consumer에 많은 유연성 제공
4.3 Efficiency
- 메세지 세트로 데이터를 묶어서 전달(small I/O 피함)
- Zero copy : Sendfile 시스템 호출 사용, 재 복사 피함
End-to-end Batch Compression
- 네트워크 대역 병목 줄임
- 여러 메세지를 묶어서 압축(단일 메세지 압축보다 효율적)
- Consumer가 이 압축을 해제
4.4 The Producer
Load balancing
- Kafka의 Producer는 리더 파티션에 직접 데이터를 전송
- Kafka 노드에 상태 등을 요청할 수 있음
- 파티션을 제어하여 데이터를 전송할 수도 있음(특정 키를 특정 파티션에)
Asynchronous send
- 단일 요청으로 더 큰 배치를 처리할 수 있도록 함
- 일정한 메세지를 고정된 시간을 초과하지 않게 전송할 수 있음
4.5 The Consumer
Push vs. pull
- Kafka는 Pull 방식으로 데이터를 처리함 (Fluem, Scibe는 Push)
- Consumer 스펙, 요구사항에 맞게 최적의 성능을 낼 수 있음
- 다른 방식의 메세지 큐들 비교 자료 : http://zzong.net/post/3
Consumer Position
- 메세지 유실 방지에 더 중점(at least once)
- 중복 전송, 성능에 영향을 줌
- Consumer 그룹은 파티션당 하나의 Consumer를 할당하여 포지션을 관리함
- 지난 포지션으로 되돌리기 가능(재적재 등)
4.6 Message Delivery Semantics
- At most once : (최대한번): 데이터유실이있을수있어, 추천하지않는방식
- At least once : (적어도 한 번): 데이터 유실은 없으나 재전송으로 인해 중복이 생길 수 있음. 대부분의 경우 충분한 방식
- Exactly once : (딱 한 번): 데이터가 오직 한 번만 처리되어 유실도 중복도 없음. 모든 상황에 대해 완벽히 보장하기 어렵지만 가장 바라는 방식
Kafka에서는 오프셋을 통해 Exactly once를 제공
4.7 Replication
- 복제의 단위는 파티션, 리더와 팔로워로 구성, 리더로만 읽기 쓰기가 가능
- 복제가 완료된(Committed) 데이터만 consumer에 제공
- Producer는 acks 옵션을 통해 복제를 제어할 수 있음
Replicated Logs: Quorums, ISRs, and State Machines (Oh my!)
- ISR(In-sync replicas)만 리더로 선출이 가능. ISR은 현재 정상적인 복제 노드. zookeeper로 계속 관리됨.
- 로그 커밋 전 실패된 데이터는 다수결로 처리
Unclean leader election: What if they all die?
- Kafka는 적어도 복제본 하나가 동기화되고 있을 경우만 데이터를 보증함
- 가용성과 데이터 일관성 중 하나를 택해야하는 상황
- 기본적으로 Kafka는 가용성을 택하고 일관성을 잃는 방식 (데이터 유실)
- unclean.leader.election.enable:true(default)
Availability and Durability Guarantees
내구성(Durability)를 높이려면
- Acks=all
- unclean.leader.election.enable false
- 최소 ISR 크기 지정 : 크게. 메세지를 더 많은 복제본에 쓰도록 (단 최소 임계값 아래가 되면 파티션을 사용할 수 없게 됨)
Replica Management
- 클러스터 내 파티션을 라운드로빈 방식으로 균형을 유지함(한쪽 노드에 큰 토픽이 몰리지 않도록)
- 브로커 중 하나는 컨트롤러(Controller) 역할 : 장애 브로커에 영향을 받는 모든 파티션의 리더를 변경함. 많은 리더쉽 관리는 일괄적으로 처리
4.8 Log Compaction
- 최소한 하나의 토픽 파티션에 메시지 키 별 마지막 값을 유지하는 것
- 기본적으로 일정 기간동안만 로그를 보관하는 기능 외
- 데이터베이스 테이블 변경과 같이 마지막 값을 유지할 필요성있는 곳에서 중요함
Log Compaction Basics
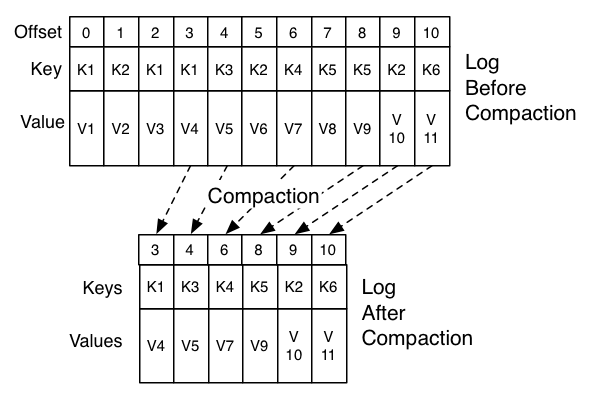
Configuring The Log Cleaner
- log.cleanup.policy = compact (default는 delete)
4.9 Quotas
- 0.9부터 제공
- 쿼터를 넘은 클라이언트는 응답시간 지연을 통해 쿼터를 제어
참고
- 카프카 소개 : http://www.slideshare.net/springloops/apache-kafka-intro20150313springloops-46067669
- Apache Kafka 0.8 basic training - Verisign : http://www.slideshare.net/miguno/apache-kafka-08-basic-training-verisign